This the multi-page printable view of this section. Click here to print.
Arsitektur Kubernetes
- 1: Node
- 2: Komunikasi antara Control Plane dan Node
- 3: Controller
- 4: Konsep-konsep di balik Controller Manager
1 - Node
Node merupakan sebuah mesin worker di dalam Kubernetes, yang sebelumnya dinamakan minion.
Sebuah node bisa berupa VM ataupun mesin fisik, tergantung dari klaster-nya.
Masing-masing node berisi beberapa servis yang berguna untuk menjalankan banyak pod dan diatur oleh komponen-komponen yang dimiliki oleh master.
Servis-servis di dalam sebuah node terdiri dari runtime kontainer, kubelet dan kube-proxy.
Untuk lebih detail, lihat dokumentasi desain arsitektur pada Node Kubernetes.
Status Node
Sebuah status node berisikan informasi sebagai berikut:
Masing-masing bagian dijelaskan secara rinci di bawah ini.
Addresses
Penggunaan field-field ini bergantung pada penyedia layanan cloud ataupun konfigurasi bare metal yang kamu punya.
- HostName: Merupakan hostname yang dilaporkan oleh kernel node. Dapat diganti melalui parameter
--hostname-overridepada kubelet. - ExternalIP: Biasanya merupakan alamat IP pada node yang punya route eksternal (bisa diakses dari luar klaster).
- InternalIP: Biasanya merupakan alamat IP pada node yang hanya punya route di dalam klaster.
Condition
Field conditions menjelaskan tentang status dari semua node yang sedang berjalan (Running).
| Kondisi Node | Penjelasan |
|---|---|
OutOfDisk |
True jika node sudah tidak punya cukup kapasitas disk untuk menjalankan pod baru, False jika sebaliknya |
Ready |
True jika node sehat (healthy) dan siap untuk menerima pod, False jika node tidak lagi sehat (unhealthy) dan tidak siap menerima pod, serta Unknown jika kontroler node tidak menerima pesan di dalam node-monitor-grace-period (standarnya 40 detik) |
MemoryPressure |
True jika memori pada node terkena tekanan (pressure) -- maksudnya, jika kapasitas memori node sudah di titik rendah; False untuk sebaliknya |
PIDPressure |
True jika process-process mengalami tekanan (pressure) -- maksudnya, jika node menjalankan terlalu banyak process; False untuk sebaliknya |
DiskPressure |
True jika ukuran disk mengalami tekanan (pressure) -- maksudnya, jika kapasitas disk sudah di titik rendah; False untuk sebaliknya |
NetworkUnavailable |
True jika jaringan untuk node tidak dikonfigurasi dengan benar, False untuk sebaliknya |
Condition pada node direpresentasikan oleh suatu obyek JSON. Sebagai contoh, respon berikut ini menggambarkan node yang sedang sehat (healthy).
"conditions": [
{
"type": "Ready",
"status": "True"
}
]
Jika status untuk Ready condition bernilai Unknown atau False untuk waktu yang lebih dari pod-eviction-timeout, tergantung bagaimana kube-controller-manager dikonfigurasi, semua pod yang dijalankan pada node tersebut akan dihilangkan oleh Kontroler Node.
Durasi eviction timeout yang standar adalah lima menit.
Pada kasus tertentu ketika node terputus jaringannya, apiserver tidak dapat berkomunikasi dengan kubelet yang ada pada node.
Keputusan untuk menghilangkan pod tidak dapat diberitahukan pada kubelet, sampai komunikasi dengan apiserver terhubung kembali.
Sementara itu, pod-pod akan terus berjalan pada node yang sudah terputus, walaupun mendapati schedule untuk dihilangkan.
Pada versi Kubernetes sebelum 1.5, kontroler node dapat menghilangkan dengan paksa (force delete) pod-pod yang terputus dari apiserver. Namun, pada versi 1.5 dan seterusnya, kontroler node tidak menghilangkan pod dengan paksa, sampai ada konfirmasi bahwa pod tersebut sudah berhenti jalan di dalam klaster. Pada kasus dimana Kubernetes tidak bisa menarik kesimpulan bahwa ada node yang telah meninggalkan klaster, admin klaster mungkin perlu untuk menghilangkan node secara manual. Menghilangkan obyek node dari Kubernetes akan membuat semua pod yang berjalan pada node tersebut dihilangkan oleh apiserver, dan membebaskan nama-namanya agar bisa digunakan kembali.
Pada versi 1.12, fitur TaintNodesByCondition telah dipromosikan ke beta, sehingga kontroler lifecycle node secara otomatis membuat taints yang merepresentasikan conditions.
Akibatnya, scheduler menghiraukan conditions ketika mempertimbangkan sebuah Node; scheduler akan melihat pada taints sebuah Node dan tolerations sebuah Pod.
Sekarang, para pengguna dapat memilih antara model scheduling yang lama dan model scheduling yang lebih fleksibel. Pada model yang lama, sebuah pod tidak memiliki tolerations apapun sampai mendapat giliran schedule. Namun, pod dapat dijalankan pada Node tertentu, dimana pod melakukan toleransi terhadap taints yang dimiliki oleh Node tersebut.
Perhatian: Mengaktifkan fitur ini menambahkan delay sedikit antara waktu saat suatu condition terlihat dan saat suatu taint dibuat. Delay ini biasanya kurang dari satu detik, tapi dapat menambahkan jumlah yang telah berhasil mendapat schedule, namun ditolak oleh kubelet untuk dijalankan.
Capacity
Menjelaskan tentang resource-resource yang ada pada node: CPU, memori, dan jumlah pod secara maksimal yang dapat dijalankan pada suatu node.
Info
Informasi secara umum pada suatu node, seperti versi kernel, versi Kubernetes (versi kubelet dan kube-proxy), versi Docker (jika digunakan), nama OS. Informasi ini dikumpulkan oleh Kubelet di dalam node.
Manajemen
Tidak seperti pod dan service, sebuah node tidaklah dibuat dan dikonfigurasi oleh Kubernetes: tapi node dibuat di luar klaster oleh penyedia layanan cloud, seperti Google Compute Engine, atau pool mesin fisik ataupun virtual (VM) yang kamu punya. Jadi ketika Kubernetes membuat sebuah node, obyek yang merepresentasikan node tersebut akan dibuat. Setelah pembuatan, Kubernetes memeriksa apakah node tersebut valid atau tidak. Contohnya, jika kamu mencoba untuk membuat node dari konten berikut:
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
}
Kubernetes membuat sebuah obyek node secara internal (representasinya), dan melakukan validasi terhadap node. Validasi dilakukan dengan memeriksa kondisi kesehatan node (health checking), berdasarkan field metadata.name. Jika node valid -- terjadi saat semua servis yang diperlukan sudah jalan -- maka node diperbolehkan untuk menjalankan sebuah pod.
Namun jika tidak valid, node tersebut akan dihiraukan untuk aktivitas apapun yang berhubungan dengan klaster, sampai telah menjadi valid.
Catatan: Kubernetes tetap menyimpan obyek untuk node yang tidak valid, dan terus memeriksa apakah node telah menjadi valid atau belum. Kamu harus secara eksplisit menghilangkan obyek Node tersebut untuk menghilangkan proses ini.
Saat ini, ada tiga komponen yang berinteraksi dengan antarmuka node di Kubernetes: kontroler node, kubelet, dan kubectl.
Kontroler Node
Kontroler node adalah komponen master Kubernetes yang berfungsi untuk mengatur berbagai aspek dari node.
Kontroler node memiliki berbagai peran (role) dalam sebuah lifecycle node. Pertama, menetapkan blok CIDR pada node tersebut saat registrasi (jika CIDR assignment diaktifkan).
Kedua, terus memperbarui daftar internal node di dalam kontroler node, sesuai dengan daftar mesin yang tersedia di dalam penyedia layanan cloud. Ketika berjalan di dalam environment cloud, kapanpun saat sebuah node tidak lagi sehat (unhealthy), kontroler node bertanya pada penyedia cloud, apakah VM untuk node tersebut masihkah tersedia atau tidak. Jika sudah tidak tersedia, kontroler node menghilangkan node tersebut dari daftar node.
Ketiga, melakukan monitor terhadap kondisi kesehatan (health) node.
Kontroler node bertanggung jawab untuk mengubah status NodeReady condition pada NodeStatus menjadi ConditionUnknown, ketika sebuah node terputus jaringannya (kontroler node tidak lagi mendapat heartbeat karena suatu hal, contohnya karena node tidak hidup), dan saat kemudian melakukan eviction terhadap semua pod yang ada pada node tersebut (melalui terminasi halus -- graceful) jika node masih terus terputus. (Timeout standar adalah 40 detik untuk mulai melaporkan ConditionUnknown dan 5 menit setelah itu untuk mulai melakukan eviction terhadap pod.)
Kontroler node memeriksa state masing-masing node untuk durasi yang ditentukan oleh argumen --node-monitor-period.
Pada versi Kubernetes sebelum 1.13, NodeStatus adalah heartbeat yang diberikan oleh node.
Setelah versi 1.13, fitur node lease diperkenalkan sebagai fitur alpha (fitur gate NodeLease,
KEP-0009).
Ketika fitur node lease diaktifasi, setiap node terhubung dengan obyek Lease di dalam namespace kube-node-lease yang terus diperbarui secara berkala.
Kemudian, NodeStatus dan node lease keduanya dijadikan sebagai heartbeat dari node.
Semua node lease diperbarui sesering mungkin, sedangkan NodeStatus dilaporkan dari node untuk master hanya ketika ada perubahan atau telah melewati periode waktu tertentu (default-nya 1 menit, lebih lama daripada default timeout node-node yang terputus jaringannya).
Karena node lease jauh lebih ringan daripada NodeStatus, fitur ini membuat heartbeat dari node jauh lebih murah secara signifikan dari sudut pandang skalabilitas dan performa.
Di Kubernetes 1.4, kami telah memperbarui logic dari kontroler node supaya lebih baik dalam menangani kasus saat banyak sekali node yang tidak bisa terhubung dengan master (contohnya, karena master punya masalah jaringan). Mulai dari 1.4, kontroler node melihat state dari semua node di dalam klaster, saat memutuskan untuk melakukan eviction pada pod.
Pada kasus kebanyakan, kontroler node membatasi rate eviction menjadi --node-eviction-rate (default-nya 0.1) per detik.
Artinya, kontroler node tidak akan melakukan eviction pada pod lebih dari 1 node per 10 detik.
Perlakuan eviction pada node berubah ketika sebuah node menjadi tidak sehat (unhealthy) di dalam suatu zona availability.
Kontroler node memeriksa berapa persentase node di dalam zona tersebut yang tidak sehat (saat NodeReady condition menjadi ConditionUnknown atau ConditionFalse) pada saat yang bersamaan.
Jika persentase node yang tidak sehat bernilai --unhealthy-zone-threshold (default-nya 0.55), maka rate eviction berkurang: untuk ukuran klaster yang kecil (saat jumlahnya lebih kecil atau sama dengan jumlah node --large-cluster-size-threshold - default-nya 50), maka eviction akan berhenti dilakukan.
Jika masih besar jumlahnya, rate eviction dikurangi menjadi --secondary-node-eviction-rate (default-nya 0.01) per detik.
Alasan kenapa hal ini diimplementasi untuk setiap zona availability adalah karena satu zona bisa saja terputus dari master, saat yang lainnya masih terhubung. Jika klaster tidak menjangkau banyak zona availability yang disediakan oleh penyedia cloud, maka hanya ada satu zona (untuk semua node di dalam klaster).
Alasan utama untuk menyebarkan node pada banyak zona availability adalah supaya workload dapat dipindahkan ke zona sehat (healthy) saat suatu zona mati secara menyeluruh.
Kemudian, jika semua node di dalam suatu zona menjadi tidak sehat (unhealthy), maka kontroler node melakukan eviction pada rate normal --node-eviction-rate.
Kasus khusus, ketika seluruh zona tidak ada satupun sehat (tidak ada node yang sehat satupun di dalam klaster).
Pada kasus ini, kontroler node berasumsi ada masalah pada jaringan master, dan menghentikan semua eviction sampai jaringan terhubung kembali.
Mulai dari Kubernetes 1.6, kontroler node juga bertanggung jawab untuk melakukan eviction pada pod-pod yang berjalan di atas node dengan taints NoExecute, ketika pod-pod tersebut sudah tidak lagi tolerate terhadap taints.
Sebagai tambahan, hal ini di-nonaktifkan secara default pada fitur alpha, kontroler node bertanggung jawab untuk menambahkan taints yang berhubungan dengan masalah pada node, seperti terputus atau NotReady.
Lihat dokumentasi ini untuk bahasan detail tentang taints NoExecute dan fitur alpha.
Mulai dari versi 1.8, kontroler node bisa diatur untuk bertanggung jawab pada pembuatan taints yang merepresentasikan node condition. Ini merupakan fitur alpha untuk versi 1.8.
Self-Registration untuk Node
Ketika argumen --register-node pada kubelet bernilai true (default-nya), kubelet akan berusaha untuk registrasi dirinya melalui API server.
Ini merupakan pattern yang disukai, digunakan oleh kebanyakan distros.
Kubelet memulai registrasi diri (self-registration) dengan opsi-opsi berikut:
--kubeconfig- Path berisi kredensial-kredensial yang digunakan untuk registrasi diri pada apiserver.--cloud-provider- Cara berbicara pada sebuah penyedia layanan cloud, baca tentang metadata-nya.--register-node- Registrasi secara otomatis pada API server.--register-with-taints- Registrasi node dengan daftar taints (dipisahkan oleh koma<key>=<value>:<effect>). No-op jikaregister-nodebernilai false.--node-ip- Alamat IP dari node dimana kubelet berjalan.--node-labels- Label-label untuk ditambahkan saat melakukan registrasi untuk node di dalam klaster (lihat label yang dibatasi secara paksa oleh NodeRestriction admission plugin untuk 1.13+).--node-status-update-frequency- Menentukan seberapa sering kubelet melaporkan status pada master.
Ketika mode otorisasi Node dan NodeRestriction admission plugin diaktifkan, semua kubelet hanya punya otoritas untuk membuat/modifikasi resource Node masing-masing.
Administrasi Node secara Manual
Seorang admin klaster dapat membuat dan memodifikasi obyek node.
Jika admin ingin untuk membuat obyek node secara manual, atur argument --register-node=false pada kubelet.
Admin dapat memodifikasi resource-resource node (terlepas dari --register-node).
Modifikasi terdiri dari pengaturan label pada node dan membuat node tidak dapat di-schedule.
Label-label pada node digunakan oleh selector node untuk mengatur proses schedule untuk pod, misalnya, membatasi sebuah pod hanya boleh dijalankan pada node-node tertentu.
Menandai sebuah node untuk tidak dapat di-schedule mencegah pod baru untuk tidak di-schedule pada node, tanpa mempengaruhi pod-pod yang sudah berjalan pada node tersebut. Ini berguna sebagai langkah persiapan untuk melakukan reboote pada node. Sebagai contoh, untuk menandai sebuah node untuk tidak dapat di-schedule, jalankan perintah berikut:
kubectl cordon $NODENAME
Catatan: Pod-pod yang dibuat oleh suatu kontroler DaemonSet menghiraukan scheduler Kubernetes dan mengabaikan tanda unschedulable pada node. Hal ini mengasumsikan bahwa daemons dimiliki oleh mesin, walaupun telah dilakukan drain pada aplikasi, saat melakukan persaiapan reboot.
Kapasitas Node
Kapasitas node (jumlah CPU dan memori) adalah bagian dari obyek node. Pada umumnya, node-node melakukan registrasi diri dan melaporkan kapasitasnya saat obyek node dibuat. Jika kamu melakukan administrasi node manual, maka kamu perlu mengatur kapasitas node saat menambahkan node baru.
Scheduler Kubernetes memastikan kalau ada resource yang cukup untuk menjalankan semua pod di dalam sebuah node. Kubernetes memeriksa jumlah semua request untuk kontainer pada sebuah node tidak lebih besar daripada kapasitas node. Hal ini termasuk semua kontainer yang dijalankan oleh kubelet. Namun, ini tidak termasuk kontainer-kontainer yang dijalankan secara langsung oleh runtime kontainer ataupun process yang ada di luar kontainer.
Kalau kamu ingin secara eksplisit menyimpan resource cadangan untuk menjalankan process-process selain Pod, ikut tutorial menyimpan resource cadangan untuk system daemon.
Obyek API
Node adalah tingkatan tertinggi dari resource di dalam Kubernetes REST API. Penjelasan lebih detail tentang obyek API dapat dilihat pada: Obyek Node API.
2 - Komunikasi antara Control Plane dan Node
Dokumen ini menjelaskan tentang jalur-jalur komunikasi di antara klaster Kubernetes dan control plane yang sebenarnya hanya berhubungan dengan apiserver saja. Kenapa ada dokumen ini? Supaya kamu, para pengguna Kubernetes, punya gambaran bagaimana mengatur instalasi untuk memperketat konfigurasi jaringan di dalam klaster. Hal ini cukup penting, karena klaster bisa saja berjalan pada jaringan tak terpercaya (untrusted network), ataupun melalui alamat-alamat IP publik pada penyedia cloud.
Node Menuju Control Plane
Kubernetes memiliki sebuah pola API "hub-and-spoke". Semua penggunaan API dari Node (atau Pod dimana Pod-Pod tersebut dijalankan) akan diterminasi pada apiserver (tidak ada satu komponen control plane apa pun yang didesain untuk diekspos pada servis remote). Apiserver dikonfigurasi untuk mendengarkan koneksi aman remote yang pada umumnya terdapat pada porta HTTPS (443) dengan satu atau lebih bentuk autentikasi klien yang dipasang. Sebaiknya, satu atau beberapa metode otorisasi juga dipasang, terutama jika kamu memperbolehkan permintaan anonim (anonymous request) ataupun service account token.
Jika diperlukan, Pod-Pod dapat terhubung pada apiserver secara aman dengan menggunakan ServiceAccount. Dengan ini, Kubernetes memasukkan public root certificate dan bearer token yang valid ke dalam Pod, secara otomatis saat Pod mulai dijalankan. Kubernetes Service (di dalam semua Namespace) diatur dengan sebuah alamat IP virtual. Semua yang mengakses alamat IP ini akan dialihkan (melalui kube-proxy) menuju endpoint HTTPS dari apiserver.
Komponen-komponen juga melakukan koneksi pada apiserver klaster melalui porta yang aman.
Akibatnya, untuk konfigurasi yang umum dan standar, semua koneksi dari klaster (node-node dan pod-pod yang berjalan di atas node tersebut) menujucontrol planesudah terhubung dengan aman. Dan juga, klaster dancontrol planebisa terhubung melalui jaringan publik dan/atau yang tak terpercaya (untrusted).
Control Plane menuju Node
Ada dua jalur komunikasi utama dari control plane (apiserver) menuju klaster. Pertama, dari apiserver ke proses kubelet yang berjalan pada setiap Node di dalam klaster. Kedua, dari apiserver ke setiap Node, Pod, ataupun Service melalui fungsi proksi pada apiserver
Apiserver menuju kubelet
Koneksi dari apiserver menuju kubelet bertujuan untuk:
- Melihat log dari pod-pod.
- Masuk ke dalam pod-pod yang sedang berjalan (attach).
- Menyediakan fungsi port-forward dari kubelet.
Semua koneksi ini diterminasi pada endpoint HTTPS dari kubelet. Secara default, apiserver tidak melakukan verifikasi serving certificate dari kubelet, yang membuat koneksi terekspos pada serangan man-in-the-middle, dan juga tidak aman untuk terhubung melalui jaringan tak terpercaya (untrusted) dan/atau publik.
Untuk melakukan verifikasi koneksi ini, berikan root certificate pada apiserver melalui tanda --kubelet-certificate-authority, sehingga apiserver dapat memverifikasi serving certificate dari kubelet.
Cara lainnya, gunakan tunnel SSH antara apiserver dan kubelet jika diperlukan, untuk menghindari komunikasi melalui jaringan tak terpercaya (untrusted) atau publik.
Terakhir, yang terpenting, aktifkan autentikasi dan/atau otorisasi Kubelet untuk mengamankan API kubelet.
Apiserver menuju Node, Pod, dan Service
Secara default, koneksi apiserver menuju node, pod atau service hanyalah melalui HTTP polos (plain), sehingga tidak ada autentikasi maupun enkripsi.
Koneksi tersebut bisa diamankan melalui HTTPS dengan menambahkan https: pada URL API dengan nama dari node, pod, atau service.
Namun, koneksi tidak tervalidasi dengan certificate yang disediakan oleh endpoint HTTPS maupun kredensial client, sehingga walaupun koneksi sudah terenkripsi, tidak ada yang menjamin integritasnya.
Koneksi ini tidak aman untuk dilalui pada jaringan publik dan/atau tak terpercaya untrusted.
Tunnel SSH
Kubernetes menyediakan tunnel SSH untuk mengamankan jalur komunikasi control plane -> Klaster. Dengan ini, apiserver menginisiasi sebuah tunnel SSH untuk setiap node di dalam klaster (terhubung ke server SSH di port 22) dan membuat semua trafik menuju kubelet, node, pod, atau service dilewatkan melalui tunnel tesebut. Tunnel ini memastikan trafik tidak terekspos keluar jaringan dimana node-node berada.
Tunnel SSH saat ini sudah usang (deprecated), jadi sebaiknya jangan digunakan, kecuali kamu tahu pasti apa yang kamu lakukan. Sebuah desain baru untuk mengganti kanal komunikasi ini sedang disiapkan.
3 - Controller
Dalam bidang robotika dan otomatisasi, control loop atau kontrol tertutup adalah lingkaran tertutup yang mengatur keadaan suatu sistem.
Berikut adalah salah satu contoh kontrol tertutup: termostat di sebuah ruangan.
Ketika kamu mengatur suhunya, itu mengisyaratkan ke termostat tentang keadaan yang kamu inginkan. Sedangkan suhu kamar yang sebenarnya adalah keadaan saat ini. Termostat berfungsi untuk membawa keadaan saat ini mendekati ke keadaan yang diinginkan, dengan menghidupkan atau mematikan perangkat.
Di Kubernetes, controller adalah kontrol tertutup yang mengawasi keadaan klaster klaster kamu, lalu membuat atau meminta perubahan jika diperlukan. Setiap controller mencoba untuk memindahkan status klaster saat ini mendekati keadaan yang diinginkan.
Di Kubernetes, pengontrol adalah kontrol tertutup yang mengawasi kondisi klaster, lalu membuat atau meminta perubahan jika diperlukan. Setiap pengontrol mencoba untuk memindahkan status klaster saat ini lebih dekat ke kondisi yang diinginkan.Pola controller
Sebuah controller melacak sekurang-kurangnya satu jenis sumber daya dari Kubernetes. objek-objek ini memiliki spec field yang merepresentasikan keadaan yang diinginkan. Satu atau lebih controller untuk resource tersebut bertanggung jawab untuk membuat keadaan sekarang mendekati keadaan yang diinginkan.
Controller mungkin saja melakukan tindakan itu sendiri; namun secara umum, di Kubernetes, controller akan mengirim pesan ke API server yang mempunyai efek samping yang bermanfaat. Kamu bisa melihat contoh-contoh di bawah ini.
Kontrol melalui server API
Controller Job adalah contoh dari controller bawaan dari Kubernetes. Controller bawaan tersebut mengelola status melalui interaksi dengan server API dari suatu klaster.
Job adalah sumber daya dalam Kubernetes yang menjalankan a Pod, atau mungkin beberapa Pod sekaligus, untuk melakukan sebuah pekerjaan dan kemudian berhenti.
(Setelah dijadwalkan, objek Pod akan menjadi bagian dari keadaan yang diinginkan oleh kubelet).
Ketika controller job melihat tugas baru, maka controller itu memastikan bahwa, di suatu tempat pada klaster kamu, kubelet dalam sekumpulan Node menjalankan Pod-Pod dengan jumlah yang benar untuk menyelesaikan pekerjaan. Controller job tidak menjalankan sejumlah Pod atau kontainer apa pun untuk dirinya sendiri. Namun, controller job mengisyaratkan kepada server API untuk membuat atau menghapus Pod. Komponen-komponen lain dalam control plane bekerja berdasarkan informasi baru (adakah Pod-Pod baru untuk menjadwalkan dan menjalankan pekerjan), dan pada akhirnya pekerjaan itu selesai.
Setelah kamu membuat Job baru, status yang diharapkan adalah bagaimana pekerjaan itu bisa selesai. Controller job membuat status pekerjaan saat ini agar mendekati dengan keadaan yang kamu inginkan: membuat Pod yang melakukan pekerjaan yang kamu inginkan untuk Job tersebut, sehingga Job hampir terselesaikan.
Controller juga memperbarui objek yang mengkonfigurasinya. Misalnya: setelah
pekerjaan dilakukan untuk Job tersebut, controller job memperbarui objek Job
dengan menandainya Finished.
(Ini hampir sama dengan bagaimana beberapa termostat mematikan lampu untuk mengindikasikan bahwa kamar kamu sekarang sudah berada pada suhu yang kamu inginkan).
Kontrol Langsung
Berbeda dengan sebuah Job, beberapa dari controller perlu melakukan perubahan sesuatu di luar dari klaster kamu.
Sebagai contoh, jika kamu menggunakan kontrol tertutup untuk memastikan apakah cukup Node dalam kluster kamu, maka controller memerlukan sesuatu di luar klaster saat ini untuk mengatur Node-Node baru apabila dibutuhkan.
controller yang berinteraksi dengan keadaan eksternal dapat menemukan keadaan yang diinginkannya melalui server API, dan kemudian berkomunikasi langsung dengan sistem eksternal untuk membawa keadaan saat ini mendekat keadaan yang diinginkan.
(Sebenarnya ada sebuah controller yang melakukan penskalaan node secara horizontal dalam klaster kamu.
Status sekarang berbanding status yang diinginkan
Kubernetes mengambil pandangan sistem secara cloud-native, dan mampu menangani perubahan yang konstan.
Klaster kamu dapat mengalami perubahan kapan saja pada saat pekerjaan sedang berlangsung dan kontrol tertutup secara otomatis memperbaiki setiap kegagalan. Hal ini berarti bahwa, secara potensi, klaster kamu tidak akan pernah mencapai kondisi stabil.
Selama controller dari klaster kamu berjalan dan mampu membuat perubahan yang bermanfaat, tidak masalah apabila keadaan keseluruhan stabil atau tidak.
Perancangan
Sebagai prinsip dasar perancangan, Kubernetes menggunakan banyak controller yang masing-masing mengelola aspek tertentu dari keadaan klaster. Yang paling umum, kontrol tertutup tertentu menggunakan salah satu jenis sumber daya sebagai suatu keadaan yang diinginkan, dan memiliki jenis sumber daya yang berbeda untuk dikelola dalam rangka membuat keadaan yang diinginkan terjadi.
Sangat penting untuk memiliki beberapa controller sederhana daripada hanya satu controller saja, dimana satu kumpulan monolitik kontrol tertutup saling berkaitan satu sama lain. Karena controller bisa saja gagal, sehingga Kubernetes dirancang untuk memungkinkan hal tersebut.
Misalnya: controller pekerjaan melacak objek pekerjaan (untuk menemukan adanya pekerjaan baru) dan objek Pod (untuk menjalankan pekerjaan tersebut dan kemudian melihat lagi ketika pekerjaan itu sudah selesai). Dalam hal ini yang lain membuat pekerjaan, sedangkan controller pekerjaan membuat Pod-Pod.
Catatan:Ada kemungkinan beberapa controller membuat atau memperbarui jenis objek yang sama. Namun di belakang layar, controller Kubernetes memastikan bahwa mereka hanya memperhatikan sumbr daya yang terkait dengan sumber daya yang mereka kendalikan.
Misalnya, kamu dapat memiliki Deployment dan Job; dimana keduanya akan membuat Pod. Controller Job tidak akan menghapus Pod yang dibuat oleh Deployment kamu, karena ada informasi (labels) yang dapat oleh controller untuk membedakan Pod-Pod tersebut.
Berbagai cara menjalankan beberapa controller
Kubernetes hadir dengan seperangkat controller bawaan yang berjalan di dalam kube-controller-manager. Beberapa controller bawaan memberikan perilaku inti yang sangat penting.
Controller Deployment dan controller Job adalah contoh dari controller yang hadir sebagai bagian dari Kubernetes itu sendiri (controller "bawaan"). Kubernetes memungkinkan kamu menjalankan control plane yang tangguh, sehingga jika ada controller bawaan yang gagal, maka bagian lain dari control plane akan mengambil alih pekerjaan.
Kamu juga dapat menemukan pengontrol yang berjalan di luar control plane, untuk mengembangkan lebih jauh Kubernetes. Atau, jika mau, kamu bisa membuat controller baru sendiri. Kamu dapat menjalankan controller kamu sendiri sebagai satu kumpulan dari beberapa Pod, atau bisa juga sebagai bagian eksternal dari Kubernetes. Manakah yang paling sesuai akan tergantung pada apa yang controller khusus itu lakukan.
Selanjutnya
- Silahkan baca tentang control plane Kubernetes
- Temukan beberapa dasar tentang objek-objek Kubernetes
- Pelajari lebih lanjut tentang Kubernetes API
- Apabila kamu ingin membuat controller sendiri, silakan lihat pola perluasan dalam memperluas Kubernetes.
4 - Konsep-konsep di balik Controller Manager
Konsep Cloud Controller Manager/CCM (jangan tertukar dengan program biner kube-controller-manager) awalnya dibuat untuk memungkinkan kode vendor cloud spesifik dan kode inti Kubernetes untuk berkembang secara independen satu sama lainnya. CCM berjalan bersama dengan komponen Master lainnya seperti Kubernetes Controller Manager, API Server, dan Scheduler. CCM juga dapat dijalankan sebagai Kubernetes Addon (tambahan fungsi terhadap Kubernetes), yang akan berjalan di atas klaster Kubernetes.
Desain CCM didasarkan pada mekanisme plugin yang memungkinkan penyedia layanan cloud untuk berintegrasi dengan Kubernetes dengan mudah dengan menggunakan plugin. Sudah ada rencana untuk pengenalan penyedia layanan cloud baru pada Kubernetes, dan memindahkan penyedia layanan cloud yang sudah ada dari model yang lama ke model CCM.
Dokumen ini mendiskusikan konsep di balik CCM dan mendetail fungsi-fungsinya.
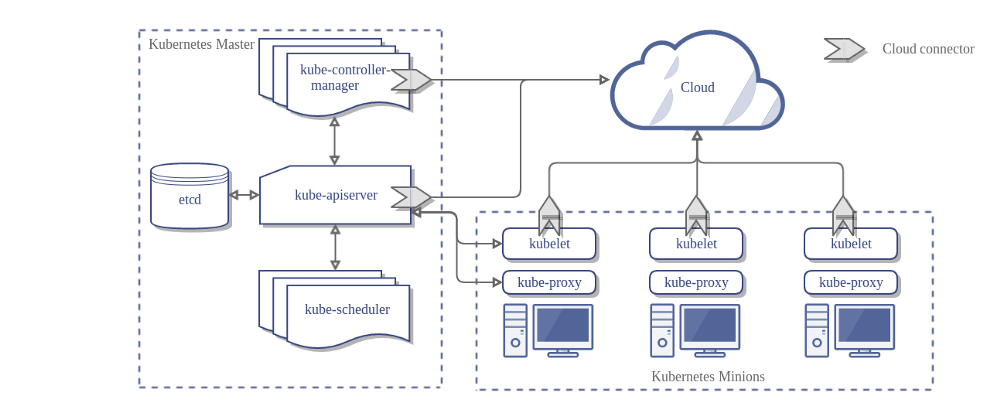
Berikut adalah arsitektur sebuah klaster Kubernetes tanpa CCM:
Desain
Pada diagram sebelumnya, Kubernetes dan penyedia layanan cloud diintegrasikan melalui beberapa komponen berbeda:
- Kubelet
- Kubernetes Controller Manager
- Kubernetes API server
CCM menggabungkan semua logika yang bergantung pada cloud dari dalam tiga komponen tersebut ke dalam sebuah titik integrasi dengan cloud. Arsitektur baru di dalam model CCM adalah sebagai berikut:
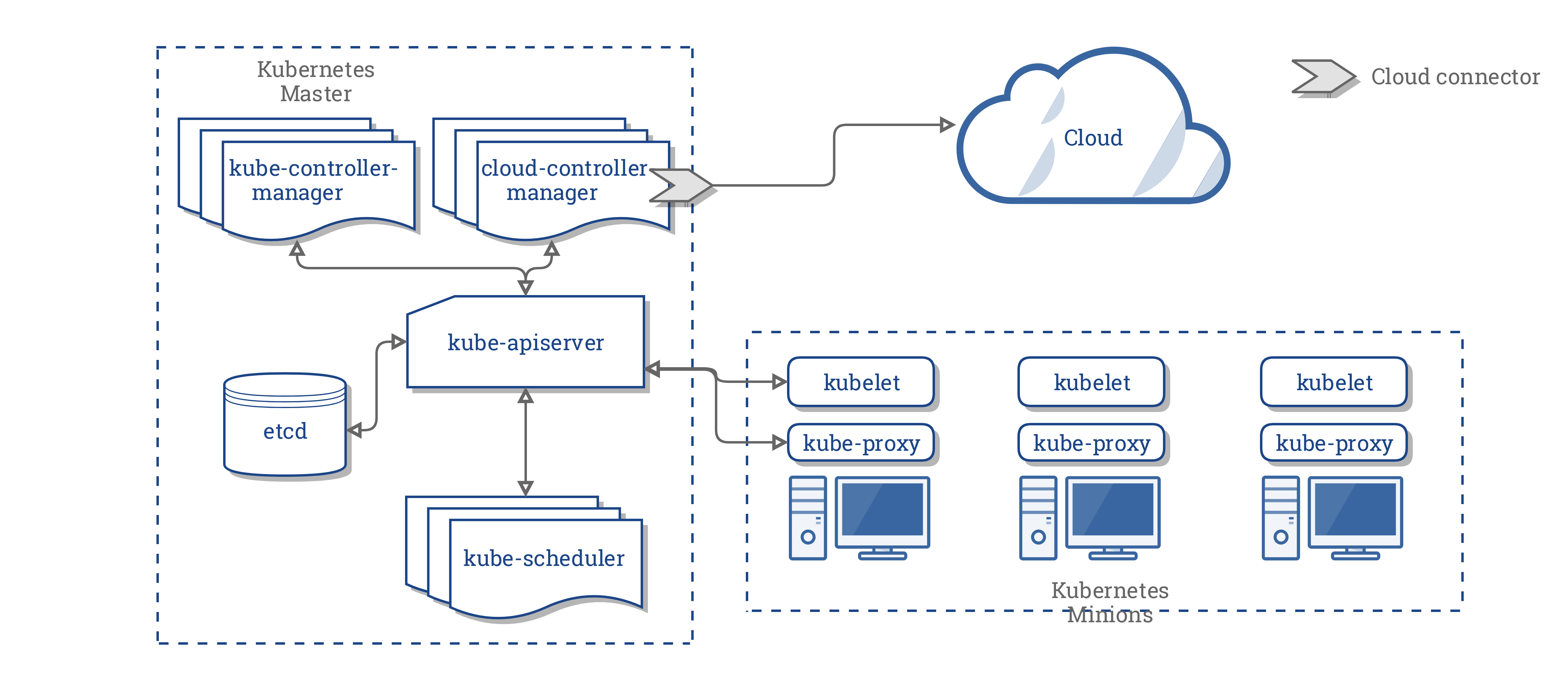
Komponen-komponen CCM
CCM memisahkan beberapa fungsi Kubernetes Controller Manager (KCM) dan menjalankannya sebagai proses yang berbeda. Secara spesifik, CCM memisahkan pengendali-pengendali (controller) di dalam KCM yang bergantung terhadap penyedia layanan cloud. KCM memiliki beberapa komponen pengendali yang bergantung pada cloud sebagai berikut:
- Node Controller
- Volume Controller
- Route Controller
- Service Controller
Pada versi 1.9, CCM menjalankan pengendali-pengendali dari daftar sebelumnya sebagai berikut:
- Node Controller
- Route Controller
- Service Controller
Catatan: Volume Controller secara sengaja tidak dipilih sebagai bagian dari CCM. Hal ini adalah karena kerumitan untuk melakukannya, dan mempertimbangkan usaha-usaha yang sedang berlangsung untuk memisahkan logika volume yang spesifik vendor dari KCM, sehingga diputuskan bahwa Volume Contoller tidak akan dipisahkan dari KCM ke CCM.
Rencana awal untuk mendukung volume menggunakan CCM adalah dengan menggunakan FlexVolume untuk mendukung penambahan volume secara pluggable. Namun, ada sebuah usaha lain yang diberi nama Container Storage Interface (CSI) yang sedang berlangsung untuk menggantikan FlexVolume.
Mempertimbangkan dinamika tersebut, kami memutuskan untuk mengambil tindakan sementara hingga CSI siap digunakan.
Fungsi-fungsi CCM
Fungsi-fungsi CCM diwarisi oleh komponen-komponen Kubernetes yang bergantung pada penyedia layanan cloud. Bagian ini disusun berdasarkan komponen-komponen tersebut.
1. Kubernetes Controller Manager
Kebanyakan fungsi CCM diturunkan dari KCM. Seperti yang telah disebutkan pada bagian sebelumnya, CCM menjalankan komponen-komponen pengendali sebagai berikut:
- Node Controller
- Route Controller
- Service Controller
Node Controller
Node Controller bertugas untuk menyiapkan sebuah node dengan cara mengambil informasi node-node yang berjalan di dalam klaster dari penyedia layanan cloud. Node Controller melakukan fungsi-fungsi berikut:
- Menyiapkan sebuah node dengan memberi label zone/region yang spesifik pada cloud.
- Menyiapkan sebuah node dengan informasi instance yang spesifik cloud , misalnya tipe dan ukurannya.
- Mendapatkan alamat jaringan dan hostname milik node tersebut.
- Dalam hal sebuah node menjadi tidak responsif, memeriksa cloud untuk melihat apakah node tersebut telah dihapus dari cloud. Juga, menghapus objek Node tersebut dari klaster Kubernetes, jika node tersebut telah dihapus dari cloud.
Route Controller
Route Controller bertugas mengkonfigurasi rute jaringan di dalam cloud secara sesuai agar Container pada node-node yang berbeda di dalam klaster Kubernetes dapat berkomunikasi satu sama lain. Route Controller hanya berlaku untuk klaster yang berjalan pada Google Compute Engine (GCE) di penyedia layanan cloud GCP.
Service Controller
Service Controller bertugas memantau terjadinya operasi create, update, dan delete pada Service. Berdasarkan keadaan terkini Service-service pada klaster Kubernetes, Service Controller mengkonfigurasi load balancer spesifik cloud (seperti ELB, Google LB, atau Oracle Cloud Infrastructure LB) agar sesuai dengan keadaan Service-service pada klaster Kubernetes. Sebagai tambahan, Service Controller juga memastikan bahwa service backend (target dari load balancer yang bersangkutan) dari load balancer cloud tersebut berada dalam kondisi terkini.
2. Kubelet
Node Controller berisi fungsi Kubelet yang bergantung pada cloud. Sebelum CCM, Kubelet bertugas untuk menyiapkan node dengan informasi spesifik cloud seperti alamat IP, label zone/region, dan tipe instance. Setelah diperkenalkannya CCM, tugas tersebut telah dipindahkan dari Kubelet ke dalam CCM.
Pada model baru ini, Kubelet menyiapkan sebuah node tanpa informasi spesifik cloud. Namun, Kubelet menambahkan sebuah Taint pada node yang baru dibuat yang menjadikan node tersebut tidak dapat dijadwalkan (sehingga tidak ada Pod yang dapat dijadwalkan ke node tersebut) hingga CCM menyiapkan node tersebut dengan informasi spesifik cloud. Setelah itu, Kubelet menghapus Taint tersebut.
Mekanisme Plugin
CCM menggunakan interface Go untuk memungkinkan implementasi dari cloud apapun untuk ditambahkan. Secara spesifik, CCM menggunakan CloudProvider Interface yang didefinisikan di sini
Implementasi dari empat kontroler-kontroler yang disorot di atas, dan beberapa kerangka kerja, bersama dengan CloudProvider Interface, akan tetap berada pada kode inti Kubernetes. Implementasi spesifik penyedia layanan cloud akan dibuat di luar kode inti dan menggunakan CloudProvider Interface yang didefinisikan di kode inti.
Untuk informasi lebih lanjut mengenai pengembangan plugin, lihat Mengembangkan Cloud Controller Manager.
Otorisasi
Bagian ini memerinci akses yang dibutuhkan oleh CCM terhadap berbagai objek API untuk melakukan tugas-tugasnya.
Akses untuk Node Controller
Node Controller hanya berinteraksi dengan objek-objek Node. Node Controller membutuhkan akses penuh untuk operasi get, list, create, update, patch, watch, dan delete terhadap objek-objek Node.
v1/Node:
- Get
- List
- Create
- Update
- Patch
- Watch
- Delete
Akses untuk Route Controller
Route Controller memantau pembuatan objek Node dan mengkonfigurasi rute jaringan secara sesuai. Route Controller membutuhkan akses untuk operasi get terhadap objek-objek Node.
v1/Node:
- Get
Akses untuk Service Controller
Service Controller memantau terjadinya operasi create, update dan delete, kemudian mengkonfigurasi Endpoint untuk Service-service tersebut secara sesuai.
Untuk mengakses Service-service, Service Controller membutuhkan akses untuk operasi list dan watch. Untuk memperbarui Service-service, dibutuhkan akses untuk operasi patch dan update.
Untuk menyiapkan Endpoint bagi untuk Service-service, dibutuhkan akses untuk operasi create, list, get, watch, dan update.
v1/Service:
- List
- Get
- Watch
- Patch
- Update
Akses Lainnya
Implementasi dari inti CCM membutuhkan akses untuk membuat Event, dan untuk memastikan operasi yang aman, dibutuhkan akses untuk membuat ServiceAccount.
v1/Event:
- Create
- Patch
- Update
v1/ServiceAccount:
- Create
Detail RBAC dari ClusterRole untuk CCM adalah sebagai berikut:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cloud-controller-manager
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- '*'
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- ""
resources:
- services
verbs:
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- update
- watch
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- get
- list
- watch
- update
Implementasi Vendor-vendor
Penyedia layanan cloud berikut telah mengimplementasikan CCM:
Administrasi Klaster
Petunjuk lengkap untuk mengkonfigurasi dan menjalankan CCM disediakan di sini.