This the multi-page printable view of this section. Click here to print.
Mengelola Sebuah Klaster
- 1: Menggunakan Calico untuk NetworkPolicy
- 2: Mengelola Memori, CPU, dan Sumber Daya API
- 3: Debugging Resolusi DNS
- 4: Kustomisasi Service DNS
- 5: Melakukan Reservasi Sumber Daya Komputasi untuk Daemon Sistem
- 6: Membagi sebuah Klaster dengan Namespace
- 7: Mengatur Control Plane Kubernetes dengan Ketersediaan Tinggi (High-Availability)
- 8: Menggunakan sysctl dalam Sebuah Klaster Kubernetes
- 9: Mengoperasikan klaster etcd untuk Kubernetes
1 - Menggunakan Calico untuk NetworkPolicy
Laman ini menunjukkan beberapa cara cepat untuk membuat klaster Calico pada Kubernetes.
Sebelum kamu memulai
Putuskan apakah kamu ingin menggelar (deploy) sebuah klaster di cloud atau di lokal.
Membuat klaster Calico dengan menggunakan Google Kubernetes Engine (GKE)
Prasyarat: gcloud.
-
Untuk meluncurkan klaster GKE dengan Calico, cukup sertakan opsi
--enable-network-policy.Sintaksis
gcloud container clusters create [CLUSTER_NAME] --enable-network-policyContoh
gcloud container clusters create my-calico-cluster --enable-network-policy -
Untuk memverifikasi penggelaran, gunakanlah perintah berikut ini.
kubectl get pods --namespace=kube-systemPod Calico dimulai dengan kata
calico. Periksa untuk memastikan bahwa statusnyaRunning.
Membuat klaster lokal Calico dengan kubeadm
Untuk membuat satu klaster Calico dengan hos tunggal dalam waktu lima belas menit dengan menggunakan kubeadm, silakan merujuk pada
Selanjutnya
Setelah klaster kamu berjalan, kamu dapat mengikuti Mendeklarasikan Kebijakan Jaringan untuk mencoba NetworkPolicy Kubernetes.
2 - Mengelola Memori, CPU, dan Sumber Daya API
2.1 - Mengatur Batas Minimum dan Maksimum Memori pada sebuah Namespace
Laman ini menunjukkan cara untuk mengatur nilai minimum dan maksimum memori yang digunakan oleh Container yang berjalan pada sebuah Namespace. Kamu dapat menentukan nilai minimum dan maksimum memori pada objek LimitRange. Jika sebuah Pod tidak memenuhi batasan yang ditentukan oleh LimitRange, maka Pod tersebut tidak dapat dibuat pada Namespace tersebut.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu belum memiliki klaster, kamu dapat membuatnya dengan menggunakan minikube, atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Untuk melihat versi, tekankubectl version.
Tiap Node dalam klastermu harus memiliki setidaknya 1 GiB memori.
Membuat sebuah Namespace
Buat sebuah Namespace sehingga sumber daya yang kamu buat pada latihan ini terisolasi dari komponen lain pada klastermu.
kubectl create namespace constraints-mem-example
Membuat LimitRange dan Pod
Berikut berkas konfigurasi untuk sebuah LimitRange:

apiVersion: v1
kind: LimitRange
metadata:
name: mem-min-max-demo-lr
spec:
limits:
- max:
memory: 1Gi
min:
memory: 500Mi
type: Container
Membuat LimitRange:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints.yaml --namespace=constraints-mem-example
Melihat informasi mendetail mengenai LimitRange:
kubectl get limitrange mem-min-max-demo-lr --namespace=constraints-mem-example --output=yaml
Keluaran yang dihasilkan menunjukkan batasan minimum dan maksimum dari memori seperti yang diharapkan. Tetapi perhatikan hal berikut, meskipun kamu tidak menentukan nilai bawaan pada berkas konfigurasi untuk LimitRange, namun nilai tersebut akan dibuat secara otomatis.
limits:
- default:
memory: 1Gi
defaultRequest:
memory: 1Gi
max:
memory: 1Gi
min:
memory: 500Mi
type: Container
Mulai sekarang setiap Container yang dibuat pada Namespace constraints-mem-example, Kubernetes akan menjalankan langkah-langkah berikut:
-
Jika Container tersebut tidak menentukan permintaan dan limit memori, maka diberikan nilai permintaan dan limit memori bawaan pada Container.
-
Memastikan Container memiliki permintaan memori yang lebih besar atau sama dengan 500 MiB.
-
Memastikan Container memiliki limit memori yang lebih kecil atau kurang dari 1 GiB.
Berikut berkas konfigurasi Pod yang memiliki satu Container. Manifes Container menentukan permintaan memori 600 MiB dan limit memori 800 MiB. Nilai tersebut memenuhi batasan minimum dan maksimum memori yang ditentukan oleh LimitRange.
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo
spec:
containers:
- name: constraints-mem-demo-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "600Mi"
Membuat Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod.yaml --namespace=constraints-mem-example
Memastikan Container pada Pod sudah berjalan:
kubectl get pod constraints-mem-demo --namespace=constraints-mem-example
Melihat informasi mendetail tentang Pod:
kubectl get pod constraints-mem-demo --output=yaml --namespace=constraints-mem-example
Keluaran yang dihasilkan menunjukkan Container memiliki permintaan memori 600 MiB dan limit memori 800 MiB. Nilai tersebut memenuhi batasan yang ditentukan oleh LimitRange.
resources:
limits:
memory: 800Mi
requests:
memory: 600Mi
Menghapus Podmu:
kubectl delete pod constraints-mem-demo --namespace=constraints-mem-example
Mencoba membuat Pod yang melebihi batasan maksimum memori
Berikut berkas konfigurasi untuk sebuah Pod yang memiliki satu Container. Container tersebut menentukan permintaan memori 800 MiB dan batas memori 1.5 GiB.
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-2
spec:
containers:
- name: constraints-mem-demo-2-ctr
image: nginx
resources:
limits:
memory: "1.5Gi"
requests:
memory: "800Mi"
Mencoba membuat Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-2.yaml --namespace=constraints-mem-example
Keluaran yang dihasilkan menunjukkan Pod tidak dibuat, karena Container menentukan limit memori yang terlalu besar:
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-2.yaml":
pods "constraints-mem-demo-2" is forbidden: maximum memory usage per Container is 1Gi, but limit is 1536Mi.
Mencoba membuat Pod yang tidak memenuhi permintaan memori
Berikut berkas konfigurasi untuk sebuah Pod yang memiliki satu Container. Container tersebut menentukan permintaan memori 100 MiB dan limit memori 800 MiB.
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-3
spec:
containers:
- name: constraints-mem-demo-3-ctr
image: nginx
resources:
limits:
memory: "800Mi"
requests:
memory: "100Mi"
Mencoba membuat Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-3.yaml --namespace=constraints-mem-example
Keluaran yang dihasilkan menunjukkan Pod tidak dibuat, karena Container menentukan permintaan memori yang terlalu kecil:
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-3.yaml":
pods "constraints-mem-demo-3" is forbidden: minimum memory usage per Container is 500Mi, but request is 100Mi.
Membuat Pod yang tidak menentukan permintaan ataupun limit memori
Berikut berkas konfigurasi untuk sebuah Pod yang memiliki satu Container. Container tersebut tidak menentukan permintaan memori dan juga limit memori.
apiVersion: v1
kind: Pod
metadata:
name: constraints-mem-demo-4
spec:
containers:
- name: constraints-mem-demo-4-ctr
image: nginx
Mencoba membuat Pod:
kubectl apply -f https://k8s.io/examples/admin/resource/memory-constraints-pod-4.yaml --namespace=constraints-mem-example
Melihat informasi mendetail tentang Pod:
kubectl get pod constraints-mem-demo-4 --namespace=constraints-mem-example --output=yaml
Keluaran yang dihasilkan menunjukkan Container pada Pod memiliki permintaan memori 1 GiB dan limit memori 1 GiB. Bagaimana Container mendapatkan nilai tersebut?
resources:
limits:
memory: 1Gi
requests:
memory: 1Gi
Karena Containermu tidak menentukan permintaan dan limit memori, Container tersebut diberikan permintaan dan limit memori bawaan dari LimitRange.
Pada tahap ini, Containermu mungkin saja berjalan ataupun mungkin juga tidak berjalan. Ingat bahwa prasyarat untuk tugas ini adalah Node harus memiliki setidaknya 1 GiB memori. Jika tiap Node hanya memiliki 1 GiB memori, maka tidak akan ada cukup memori untuk dialokasikan pada setiap Node untuk memenuhi permintaan 1 Gib memori. Jika ternyata kamu menggunakan Node dengan 2 GiB memori, maka kamu mungkin memiliki cukup ruang untuk memenuhi permintaan 1 GiB tersebut.
Menghapus Pod:
kubectl delete pod constraints-mem-demo-4 --namespace=constraints-mem-example
Pelaksanaan batasan minimum dan maksimum memori
Batasan maksimum dan minimum memori yang yang ditetapkan pada sebuah Namespace oleh LimitRange dilaksanakan hanya ketika Pod dibuat atau diperbarui. Jika kamu mengubah LimitRange, hal tersebut tidak akan memengaruhi Pods yang telah dibuat sebelumnya.
Motivasi untuk batasan minimum dan maksimum memori
Sebagai seorang administrator klaster, kamu mungkin ingin menetapkan pembatasan jumlah memori yang dapat digunakan oleh Pod. Sebagai contoh:
-
Tiap Node dalam sebuah klaster memiliki 2 GB memori. Kamu tidak ingin menerima Pod yang meminta lebih dari 2 GB memori, karena tidak ada Node pada klater yang dapat memenuhi permintaan tersebut.
-
Sebuah klaster digunakan bersama pada departemen produksi dan pengembangan. Kamu ingin mengizinkan beban kerja (workload) pada produksi untuk menggunakan hingga 8 GB memori, tapi kamu ingin beban kerja pada pengembangan cukup terbatas sampai dengan 512 MB saja. Kamu membuat Namespace terpisah untuk produksi dan pengembangan, dan kamu menerapkan batasan memori pada tiap Namespace.
Bersih-bersih
Menghapus Namespace:
kubectl delete namespace constraints-mem-example
Selanjutnya
Untuk administrator klaster
-
Mengatur Permintaan dan Limit Memori Bawaan untuk Sebuah Namespace
-
Mengatur Permintaan dan Limit CPU Bawaan untuk Sebuah Namespace
-
Mengatur Batas Minimum dan Maksimum CPU untuk Sebuah Namespace
Untuk pengembang aplikasi
3 - Debugging Resolusi DNS
Laman ini menyediakan beberapa petunjuk untuk mendiagnosis masalah DNS.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu belum memiliki klaster, kamu dapat membuatnya dengan menggunakan minikube, atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Klaster kamu harus dikonfigurasi untuk menggunakan addon CoreDNS atau pendahulunya, kube-dns.
Kubernetes servermu harus dalam versi yang sama atau lebih baru dari v1.6.
Untuk melihat versi, tekan kubectl version.
Membuat Pod sederhana yang digunakan sebagai lingkungan pengujian
apiVersion: v1
kind: Pod
metadata:
name: dnsutils
namespace: default
spec:
containers:
- name: dnsutils
image: gcr.io/kubernetes-e2e-test-images/dnsutils:1.3
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
restartPolicy: Always
Gunakan manifes berikut untuk membuat sebuah Pod:
kubectl apply -f https://k8s.io/examples/admin/dns/dnsutils.yaml
pod/dnsutils created
…dan verifikasi statusnya:
kubectl get pods dnsutils
NAME READY STATUS RESTARTS AGE
dnsutils 1/1 Running 0 <some-time>
Setelah Pod tersebut berjalan, kamu dapat menjalankan perintah nslookup di lingkungan tersebut.
Jika kamu melihat hal seperti ini, maka DNS sudah berjalan dengan benar.
kubectl exec -i -t dnsutils -- nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10
Name: kubernetes.default
Address 1: 10.0.0.1
Jika perintah nslookup gagal, periksa hal berikut:
Periksa konfigurasi DNS lokal terlebih dahulu
Periksa isi dari berkas resolv.conf. (Lihat Inheriting DNS dari node dan Isu-isu yang dikenal di bawah ini untuk informasi lebih lanjut)
kubectl exec -ti dnsutils -- cat /etc/resolv.conf
Verifikasi path pencarian dan nama server telah dibuat agar tampil seperti di bawah ini (perlu diperhatikan bahwa path pencarian dapat berbeda tergantung dari penyedia layanan cloud):
search default.svc.cluster.local svc.cluster.local cluster.local google.internal c.gce_project_id.internal
nameserver 10.0.0.10
options ndots:5
Kesalahan yang muncul berikut ini mengindikasikan terdapat masalah dengan add-on CoreDNS (atau kube-dns) atau Service terkait:
kubectl exec -i -t dnsutils -- nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10
nslookup: can't resolve 'kubernetes.default'
atau
kubectl exec -i -t dnsutils -- nslookup kubernetes.default
Server: 10.0.0.10
Address 1: 10.0.0.10 kube-dns.kube-system.svc.cluster.local
nslookup: can't resolve 'kubernetes.default'
Periksa apakah Pod DNS sedang berjalan
Gunakan perintah kubectl get pods untuk memverifikasi apakah Pod DNS sedang berjalan.
kubectl get pods --namespace=kube-system -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
...
coredns-7b96bf9f76-5hsxb 1/1 Running 0 1h
coredns-7b96bf9f76-mvmmt 1/1 Running 0 1h
...
Catatan: Nilai dari labelk8s-appadalahkube-dnsbaik untuk CoreDNS maupun kube-dns.
Jika kamu melihat tidak ada Pod CoreDNS yang sedang berjalan atau Pod tersebut gagal/telah selesai, add-on DNS mungkin tidak dijalankan (deployed) secara bawaan di lingkunganmu saat ini dan kamu harus menjalankannya secara manual.
Periksa kesalahan pada Pod DNS
Gunakan perintah kubectl logs untuk melihat log dari Container DNS.
Untuk CoreDNS:
kubectl logs --namespace=kube-system -l k8s-app=kube-dns
Berikut contoh log dari CoreDNS yang sehat (healthy):
.:53
2018/08/15 14:37:17 [INFO] CoreDNS-1.2.2
2018/08/15 14:37:17 [INFO] linux/amd64, go1.10.3, 2e322f6
CoreDNS-1.2.2
linux/amd64, go1.10.3, 2e322f6
2018/08/15 14:37:17 [INFO] plugin/reload: Running configuration MD5 = 24e6c59e83ce706f07bcc82c31b1ea1c
Periksa jika ada pesan mencurigakan atau tidak terduga dalam log.
Apakah layanan DNS berjalan?
Verifikasi apakah layanan DNS berjalan dengan menggunakan perintah kubectl get service.
kubectl get svc --namespace=kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP 1h
...
Catatan: Nama layanan adalahkube-dnsbaik untuk CoreDNS maupun kube-dns.
Jika kamu telah membuat Service atau seharusnya Service telah dibuat secara bawaan namun ternyata tidak muncul, lihat debugging Service untuk informasi lebih lanjut.
Apakah endpoint DNS telah ekspos?
Kamu dapat memverifikasikan apakah endpoint DNS telah diekspos dengan menggunakan perintah kubectl get endpoints.
kubectl get endpoints kube-dns --namespace=kube-system
NAME ENDPOINTS AGE
kube-dns 10.180.3.17:53,10.180.3.17:53 1h
Jika kamu tidak melihat endpoint, lihat bagian endpoint pada dokumentasi debugging Service.
Untuk tambahan contoh Kubernetes DNS, lihat contoh cluster-dns pada repositori Kubernetes GitHub.
Apakah kueri DNS diterima/diproses?
Kamu dapat memverifikasi apakah kueri telah diterima oleh CoreDNS dengan menambahkan plugin log pada konfigurasi CoreDNS (alias Corefile).
CoreDNS Corefile disimpan pada ConfigMap dengan nama coredns. Untuk mengeditnya, gunakan perintah:
kubectl -n kube-system edit configmap coredns
Lalu tambahkan log pada bagian Corefile seperti contoh berikut:
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
log
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
proxy . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
Setelah perubahan disimpan, perubahan dapat memakan waktu satu hingga dua menit untuk Kubernetes menyebarkan perubahan ini pada Pod CoreDNS.
Berikutnya, coba buat beberapa kueri dan lihat log pada bagian atas dari dokumen ini. Jika pod CoreDNS menerima kueri, kamu seharusnya akan melihatnya pada log.
Berikut ini contoh kueri yang terdapat di dalam log:
.:53
2018/08/15 14:37:15 [INFO] CoreDNS-1.2.0
2018/08/15 14:37:15 [INFO] linux/amd64, go1.10.3, 2e322f6
CoreDNS-1.2.0
linux/amd64, go1.10.3, 2e322f6
2018/09/07 15:29:04 [INFO] plugin/reload: Running configuration MD5 = 162475cdf272d8aa601e6fe67a6ad42f
2018/09/07 15:29:04 [INFO] Reloading complete
172.17.0.18:41675 - [07/Sep/2018:15:29:11 +0000] 59925 "A IN kubernetes.default.svc.cluster.local. udp 54 false 512" NOERROR qr,aa,rd,ra 106 0.000066649s
Isu-isu yang Dikenal
Beberapa distribusi Linux (contoh Ubuntu) menggunakan resolver DNS lokal secara bawaan (systemd-resolved).
Systemd-resolved memindahkan dan mengganti /etc/resolv.conf dengan berkas stub yang dapat menyebabkan forwarding loop yang fatal saat meresolusi nama pada server upstream. Ini dapat diatasi secara manual dengan menggunakan flag kubelet --resolv-conf
untuk mengarahkan ke resolv.conf yang benar (Pada systemd-resolved, ini berada di /run/systemd/resolve/resolv.conf).
kubeadm akan otomatis mendeteksi systemd-resolved, dan menyesuaikan flag kubelet sebagai mana mestinya.
Pemasangan Kubernetes tidak menggunakan berkas resolv.conf pada node untuk digunakan sebagai klaster DNS secara default, karena proses ini umumnya spesifik pada distribusi tertentu. Hal ini bisa jadi akan diimplementasi nantinya.
Libc Linux (alias glibc) secara bawaan memiliki batasan nameserver DNS sebanyak 3 rekaman (records). Selain itu, pada glibc versi yang lebih lama dari glibc-2.17-222 (versi terbaru lihat isu ini), jumlah rekaman DNS search dibatasi sejumlah 6 (lihat masalah sejak 2005 ini). Kubernetes membutuhkan 1 rekaman nameserver dan 3 rekaman search. Ini berarti jika instalasi lokal telah menggunakan 3 nameserver atau menggunakan lebih dari 3 search,sementara versi glibc kamu termasuk yang terkena dampak, beberapa dari pengaturan tersebut akan hilang. Untuk menyiasati batasan rekaman DNS nameserver, node dapat menjalankan dnsmasq,yang akan menyediakan nameserver lebih banyak. Kamu juga dapat menggunakan kubelet --resolv-conf flag. Untuk menyiasati batasan rekaman search, pertimbangkan untuk memperbarui distribusi linux kamu atau memperbarui glibc ke versi yang tidak terdampak.
Jika kamu menggunakan Alpine versi 3.3 atau lebih lama sebagai dasar image kamu, DNS mungkin tidak dapat bekerja dengan benar disebabkan masalah dengan Alpine. Masalah 30215 Kubernetes menyediakan informasi lebih detil tentang ini.
Selanjutnya
4 - Kustomisasi Service DNS
Laman ini menjelaskan cara mengonfigurasi DNS Pod kamu dan menyesuaikan proses resolusi DNS pada klaster kamu.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu belum memiliki klaster, kamu dapat membuatnya dengan menggunakan minikube, atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Klaster kamu harus menjalankan tambahan (add-on) CoreDNS terlebih dahulu.
Migrasi ke CoreDNS
menjelaskan tentang bagaimana menggunakan kubeadm untuk melakukan migrasi dari kube-dns.
Kubernetes servermu harus dalam versi yang sama atau lebih baru dari v1.12.
Untuk melihat versi, tekan kubectl version.
Pengenalan
DNS adalah Service bawaan dalam Kubernetes yang diluncurkan secara otomatis melalui addon manager add-on klaster.
Sejak Kubernetes v1.12, CoreDNS adalah server DNS yang direkomendasikan untuk menggantikan kube-dns. Jika klaster kamu
sebelumnya menggunakan kube-dns, maka kamu mungkin masih menggunakan kube-dns daripada CoreDNS.
Catatan: Baik Service CoreDNS dan kube-dns diberi namakube-dnspada fieldmetadata.name. Hal ini agar ada interoperabilitas yang lebih besar dengan beban kerja yang bergantung pada nama Servicekube-dnslama untuk me-resolve alamat internal ke dalam klaster. Dengan menggunakan sebuah Service yang bernamakube-dnsmengabstraksi detail implementasi yang dijalankan oleh penyedia DNS di belakang nama umum tersebut.
Jika kamu menjalankan CoreDNS sebagai sebuah Deployment, maka biasanya akan ditampilkan sebagai sebuah Service Kubernetes dengan alamat IP yang statis.
Kubelet meneruskan informasi DNS resolver ke setiap Container dengan argumen --cluster-dns=<dns-service-ip>.
Nama DNS juga membutuhkan domain. Kamu dapat mengonfigurasi domain lokal di kubelet
dengan argumen --cluster-domain=<default-local-domain>.
Server DNS mendukung forward lookup (record A dan AAAA), port lookup (record SRV), reverse lookup alamat IP (record PTR), dan lain sebagainya. Untuk informasi lebih lanjut, lihatlah DNS untuk Service dan Pod.
Jika dnsPolicy dari Pod diatur menjadi default, itu berarti mewarisi konfigurasi resolusi nama
dari Node yang dijalankan Pod. Resolusi DNS pada Pod
harus berperilaku sama dengan Node tersebut.
Tapi lihat Isu-isu yang telah diketahui.
Jika kamu tidak menginginkan hal ini, atau jika kamu menginginkan konfigurasi DNS untuk Pod berbeda, kamu bisa
menggunakan argumen --resolv-conf pada kubelet. Atur argumen ini menjadi "" untuk mencegah Pod tidak
mewarisi konfigurasi DNS. Atur ke jalur (path) berkas yang tepat untuk berkas yang berbeda dengan
/etc/resolv.conf untuk menghindari mewarisi konfigurasi DNS.
CoreDNS
CoreDNS adalah server DNS otoritatif untuk kegunaan secara umum yang dapat berfungsi sebagai Service DNS untuk klaster, yang sesuai dengan spesifikasi dns.
Opsi ConfigMap pada CoreDNS
CoreDNS adalah server DNS yang modular dan mudah dipasang, dan setiap plugin dapat menambahkan fungsionalitas baru ke CoreDNS. Fitur ini dapat dikonfigurasikan dengan menjaga berkas Corefile, yang merupakan berkas konfigurasi dari CoreDNS. Sebagai administrator klaster, kamu dapat memodifikasi ConfigMap untuk Corefile dari CoreDNS dengan mengubah cara perilaku pencarian Service DNS pada klaster tersebut.
Di Kubernetes, CoreDNS diinstal dengan menggunakan konfigurasi Corefile bawaan sebagai berikut:
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
Konfigurasi Corefile meliputi plugin berikut ini dari CoreDNS:
- errors: Kesalahan yang ditampilkan ke output standar (stdout)
- health: Kesehatan dari CoreDNS dilaporkan pada
http://localhost:8080/health. Dalam sintaks yang diperluaslameduckakan menangani proses tidak sehat agar menunggu selama 5 detik sebelum proses tersebut dimatikan. - ready: Endpoint HTTP pada port 8181 akan mengembalikan OK 200, ketika semua plugin yang dapat memberi sinyal kesiapan, telah memberikan sinyalnya.
- kubernetes: CoreDNS akan menjawab pertanyaan (query) DNS berdasarkan IP Service dan Pod pada Kubernetes. Kamu dapat menemukan lebih detail tentang plugin itu dalam situs web CoreDNS.
ttlmemungkinkan kamu untuk mengatur TTL khusus untuk respon dari pertanyaan DNS. Standarnya adalah 5 detik. TTL minimum yang diizinkan adalah 0 detik, dan maksimum hanya dibatasi sampai 3600 detik. Mengatur TTL ke 0 akan mencegah record untuk di simpan sementara dalam cache.
Opsipods insecuredisediakan untuk kompatibilitas dengan Service kube-dns sebelumnya. Kamu dapat menggunakan opsipods verified, yang mengembalikan record A hanya jika ada Pod pada Namespace yang sama untuk alamat IP yang sesuai. Opsipods disableddapat digunakan jika kamu tidak menggunakan record Pod. - prometheus: Metrik dari CoreDNS tersedia pada
http://localhost:9153/metricsdalam format yang sesuai dengan Prometheus (dikenal juga sebagai OpenMetrics). - forward: Setiap pertanyaan yang tidak berada dalam domain klaster Kubernetes akan diteruskan ke resolver yang telah ditentukan dalam berkas (/etc/resolv.conf).
- cache: Ini untuk mengaktifkan frontend cache.
- loop: Mendeteksi forwarding loop sederhana dan menghentikan proses CoreDNS jika loop ditemukan.
- reload: Mengizinkan reload otomatis Corefile yang telah diubah. Setelah kamu mengubah konfigurasi ConfigMap, beri waktu sekitar dua menit agar perubahan yang kamu lakukan berlaku.
- loadbalance: Ini adalah load balancer DNS secara round-robin yang mengacak urutan record A, AAAA, dan MX dalam setiap responnya.
Kamu dapat memodifikasi perilaku CoreDNS bawaan dengan memodifikasi ConfigMap.
Konfigurasi Stub-domain dan Nameserver Upstream dengan menggunakan CoreDNS
CoreDNS memiliki kemampuan untuk mengonfigurasi stubdomain dan nameserver upstream dengan menggunakan plugin forward.
Contoh
Jika operator klaster memiliki sebuah server domain Consul yang terletak di 10.150.0.1, dan semua nama Consul memiliki akhiran .consul.local. Untuk mengonfigurasinya di CoreDNS, administrator klaster membuat bait (stanza) berikut dalam ConfigMap CoreDNS.
consul.local:53 {
errors
cache 30
forward . 10.150.0.1
}
Untuk memaksa secara eksplisit semua pencarian DNS non-cluster melalui nameserver khusus pada 172.16.0.1, arahkan forward ke nameserver bukan ke /etc/resolv.conf
forward . 172.16.0.1
ConfigMap terakhir bersama dengan konfigurasi Corefile bawaan terlihat seperti berikut:
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
forward . 172.16.0.1
cache 30
loop
reload
loadbalance
}
consul.local:53 {
errors
cache 30
forward . 10.150.0.1
}
Perangkat kubeadm mendukung terjemahan otomatis dari ConfigMap kube-dns
ke ConfigMap CoreDNS yang setara.
Catatan: Sementara ini kube-dns dapat menerima FQDN untuk stubdomain dan nameserver (mis: ns.foo.com), namun CoreDNS belum mendukung fitur ini. Selama penerjemahan, semua nameserver FQDN akan dihilangkan dari konfigurasi CoreDNS.
Konfigurasi CoreDNS yang setara dengan kube-dns
CoreDNS mendukung fitur kube-dns dan banyak lagi lainnya.
ConfigMap dibuat agar kube-dns mendukung StubDomains dan upstreamNameservers untuk diterjemahkan ke plugin forward dalam CoreDNS.
Begitu pula dengan plugin Federations dalam kube-dns melakukan translasi untuk plugin federation dalam CoreDNS.
Contoh
Contoh ConfigMap ini untuk kube-dns menentukan federasi, stub domain dan server upstream nameserver:
apiVersion: v1
data:
federations: |
{"foo" : "foo.feddomain.com"}
stubDomains: |
{"abc.com" : ["1.2.3.4"], "my.cluster.local" : ["2.3.4.5"]}
upstreamNameservers: |
["8.8.8.8", "8.8.4.4"]
kind: ConfigMap
Untuk konfigurasi yang setara dengan CoreDNS buat Corefile berikut:
- Untuk federasi:
federation cluster.local {
foo foo.feddomain.com
}
- Untuk stubDomain:
abc.com:53 {
errors
cache 30
forward . 1.2.3.4
}
my.cluster.local:53 {
errors
cache 30
forward . 2.3.4.5
}
Corefile lengkap dengan plugin bawaan:
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
federation cluster.local {
foo foo.feddomain.com
}
prometheus :9153
forward . 8.8.8.8 8.8.4.4
cache 30
}
abc.com:53 {
errors
cache 30
forward . 1.2.3.4
}
my.cluster.local:53 {
errors
cache 30
forward . 2.3.4.5
}
Migrasi ke CoreDNS
Untuk bermigrasi dari kube-dns ke CoreDNS, artikel blog yang detail tersedia untuk membantu pengguna mengadaptasi CoreDNS sebagai pengganti dari kube-dns.
Kamu juga dapat bermigrasi dengan menggunakan skrip deploy CoreDNS yang resmi.
Selanjutnya
5 - Melakukan Reservasi Sumber Daya Komputasi untuk Daemon Sistem
Node Kubernetes dapat dijadwalkan sesuai dengan kapasitas. Secara bawaan, Pod dapat menggunakan semua kapasitas yang tersedia pada sebuah Node. Ini merupakan masalah karena Node sebenarnya menjalankan beberapa daemon sistem yang diperlukan oleh OS dan Kubernetes itu sendiri. Jika sumber daya pada Node tidak direservasi untuk daemon-daemon tersebut, maka Pod dan daemon akan berlomba-lomba menggunakan sumber daya yang tersedia, sehingga menyebabkan starvation sumber daya pada Node.
Fitur bernama Allocatable pada Node diekspos oleh kubelet yang berfungsi untuk melakukan
reservasi sumber daya komputasi untuk daemon sistem. Kubernetes merekomendasikan admin
klaster untuk mengatur Allocatable pada Node berdasarkan tingkat kepadatan (density) beban kerja setiap Node.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu belum memiliki klaster, kamu dapat membuatnya dengan menggunakan minikube, atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Kubernetes servermu harus dalam versi yang sama atau lebih baru dari 1.8. Untuk melihat versi, tekankubectl version.
Kamu harus menjalankan Kubernetes server dengan versi 1.17 atau yang lebih baru
untuk menggunakan perintah baris kubelet dengan opsi --reserved-cpus untuk
menyetel daftar reservasi CPU secara eksplisit.
Allocatable pada Node
Kapasitas Node
------------------------------
| kube-reserved |
|----------------------------|
| system-reserved |
|----------------------------|
| eviction-threshold |
| (batas pengusiran) |
|----------------------------|
| |
| allocatable |
| (dapat digunakan oleh Pod) |
| |
| |
------------------------------
Allocatable atau sumber daya yang dialokasikan pada sebuah Node Kubernetes merupakan
jumlah sumber daya komputasi yang dapat digunakan oleh Pod. Penjadwal tidak
dapat melakukan penjadwalan melebihi Allocatable. Saat ini dukungan terhadap
CPU, memory dan ephemeral-storage tersedia.
Allocatable pada Node diekspos oleh objek API v1.Node dan merupakan
bagian dari baris perintah kubectl describe node.
Sumber daya dapat direservasi untuk dua kategori daemon sistem melalui kubelet.
Mengaktifkan QoS dan tingkatan cgroup dari Pod
Untuk menerapkan batasan Allocatable pada Node, kamu harus mengaktifkan
hierarki cgroup yang baru melalui flag --cgroups-per-qos. Secara bawaan, flag ini
telah aktif. Saat aktif, kubelet akan memasukkan semua Pod pengguna di bawah
sebuah hierarki cgroup yang dikelola oleh kubelet.
Mengonfigurasi driver cgroup
Manipulasi terhadap hierarki cgroup pada hos melalui driver cgroup didukung oleh kubelet.
Driver dikonfigurasi melalui flag --cgroup-driver.
Nilai yang didukung adalah sebagai berikut:
cgroupfsmerupakan driver bawaan yang melakukan manipulasi secara langsung terhadap filesystem cgroup pada hos untuk mengelola sandbox cgroup.systemdmerupakan driver alternatif yang mengelola sandbox cgroup menggunakan bagian dari sumber daya yang didukung oleh sistem init yang digunakan.
Tergantung dari konfigurasi runtime Container yang digunakan,
operator dapat memilih driver cgroup tertentu untuk memastikan perilaku sistem yang tepat.
Misalnya, jika operator menggunakan driver cgroup systemd yang disediakan oleh
runtime docker, maka kubelet harus diatur untuk menggunakan driver cgroup systemd.
Kube Reserved
- Flag Kubelet:
--kube-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi][,][pid=1000] - Flag Kubelet:
--kube-reserved-cgroup=
kube-reserved berfungsi untuk mengambil informasi sumber daya reservasi
untuk daemon sistem Kubernetes, seperti kubelet, runtime Container, detektor masalah pada Node, dsb.
kube-reserved tidak berfungsi untuk mereservasi sumber daya untuk daemon sistem yang berjalan
sebagai Pod. kube-reserved merupakan fungsi dari kepadatan Pod pada Node.
Selain dari cpu, memory, dan ephemeral-storage,pid juga dapat
diatur untuk mereservasi jumlah ID proses untuk daemon sistem Kubernetes.
Secara opsional, kamu dapat memaksa daemon sistem melalui setelan kube-reserved.
Ini dilakukan dengan menspesifikasikan parent cgroup sebagai nilai dari flag --kube-reserved-cgroup pada kubelet.
Kami merekomendasikan daemon sistem Kubernetes untuk ditempatkan pada
tingkatan cgroup yang tertinggi (contohnya, runtime.slice pada mesin systemd).
Secara ideal, setiap daemon sistem sebaiknya dijalankan pada child cgroup
di bawah parent ini. Lihat dokumentasi
untuk mengetahui rekomendasi hierarki cgroup secara detail.
Catatan: kubelet tidak membuat --kube-reserved-cgroup jika cgroup
yang diberikan tidak ada pada sistem. Jika cgroup yang tidak valid diberikan,
maka kubelet akan mengalami kegagalan.
System Reserved
- Flag Kubelet:
--system-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi][,][pid=1000] - Flag Kubelet:
--system-reserved-cgroup=
system-reserved berfungsi untuk mengetahui reservasi sumber daya untuk
daemon sistem pada OS, seperti sshd, udev, dan lainnya. system-reserved sebaiknya
mereservasi memori untuk kernel juga, karena memori kernel tidak termasuk dalam
hitungan kalkulasi Pod pada Kubernetes. Kami juga merekomendasikan reservasi sumber daya
untuk sesi (session) login pengguna (contohnya, user.slice di dalam dunia systemd).
Melakukan Reservasi Daftar CPU secara Eksplisit
Kubernetes v1.17 [stable]
- Flag Kubelet:
--reserved-cpus=0-3
reserved-cpus berfungsi untuk mendefinisikan cpuset secara eksplisit untuk
daemon sistem OS dan daemon sistem Kubernetes. reserved-cpus dimaksudkan untuk
sistem-sistem yang tidak mendefinisikan tingkatan cgroup tertinggi secara terpisah untuk
daemon sistem OS dan daemon sistem Kubernetes yang berkaitan dengan sumber daya cpuset.
Jika kubelet tidak memiliki --system-reserved-cgroup dan --kube-reserved-cgroup,
cpuset akan diberikan secara eksplisit oleh reserved-cpus, yang akan menimpa definisi
yang diberikan oleh opsi --kube-reserved dan --system-reserved.
Opsi ini dirancang secara spesifik untuk kasus-kasus Telco/NFV, di mana interrupt atau timer yang tidak terkontrol bisa memengaruhi performa dari beban kerja. Kamu dapat menggunakan opsi untuk untuk mendefinisikan cpuset secara eksplisit untuk daemon sistem/Kubernetes dan interrupt/timer, sehingga CPU sisanya dalam sistem akan digunakan untuk beban kerja saja, dengan dampak yang sedikit terhadap interrupt/timer yang tidak terkontrol. Untuk memindahkan daemon sistem, daemon Kubernetes serta interrrupt/timer Kubernetes supaya menggunakan cpuset yang eksplisit didefinisikan oleh opsi ini, sebaiknya digunakan mekanisme lain di luar Kubernetes. Contohnya: pada Centos, kamu dapat melakukan ini dengan menggunakan toolset yang sudah disetel.
Batas Pengusiran (Eviction Threshold)
- Flag Kubelet:
--eviction-hard=[memory.available<500Mi]
Tekanan memori pada tingkatan Node menyebabkan sistem OOM (Out Of Memory) yang
berdampak pada Node secara keseluruhan dan semua Pod yang dijalankan di dalamnya.
Node dapat berubah menjadi offline sementara sampai memori berhasil diklaim kembali.
Untuk menghindari sistem OOM, atau mengurangi kemungkinan terjadinya OOM, kubelet
menyediakan fungsi untuk pengelolaan saat Kehabisan Sumber Daya (Out of Resource).
Pengusiran dapat dilakukan hanya untuk kasus kehabisan memory dan ephemeral-storage. Dengan mereservasi
sebagian memori melalui flag --eviction-hard, kubelet akan berusaha untuk "mengusir" (evict)
Pod ketika ketersediaan memori pada Node jatuh di bawah nilai yang telah direservasi.
Dalam bahasa sederhana, jika daemon sistem tidak ada pada Node, maka Pod tidak dapat menggunakan
memori melebihi nilai yang ditentukan oleh flag --eviction-hard. Karena alasan ini,
sumber daya yang direservasi untuk pengusiran tidak tersedia untuk Pod.
Memaksakan Allocatable pada Node
- Flag Kubelet:
--enforce-node-allocatable=pods[,][system-reserved][,][kube-reserved]
Penjadwal menganggap Allocatable sebagai kapasitas yang tersedia untuk digunakan oleh Pod.
Secara bawaan, kubelet memaksakan Allocatable untuk semua Pod. Pemaksaan dilakukan
dengan cara "mengusir" Pod-Pod ketika penggunaan sumber daya Pod secara keseluruhan telah
melewati nilai Allocatable. Lihat bagian ini
untuk mengetahui kebijakan pengusiran secara detail. Pemaksaan ini dikendalikan dengan
cara memberikan nilai Pod melalui flag --enforce-node-allocatable pada kubelet.
Secara opsional, kubelet dapat diatur untuk memaksakan kube-reserved dan
system-reserved dengan memberikan nilai melalui flag tersebut. Sebagai catatan,
jika kamu mengatur kube-reserved, maka kamu juga harus mengatur --kube-reserved-cgroup. Begitu pula
jika kamu mengatur system-reserved, maka kamu juga harus mengatur --system-reserved-cgroup.
Panduan Umum
Daemon sistem dilayani mirip seperti Pod Guaranteed yang terjamin sumber dayanya.
Daemon sistem dapat melakukan burst di dalam jangkauan cgroup. Perilaku ini
dikelola sebagai bagian dari penggelaran (deployment) Kubernetes. Sebagai contoh,
kubelet harus memiliki cgroup sendiri dan membagikan sumber daya kube-reserved dengan
runtime Container. Namun begitu, kubelet tidak dapat melakukan burst dan menggunakan
semua sumber daya yang tersedia pada Node jika kube-reserved telah dipaksakan pada sistem.
Kamu harus berhati-hati ekstra ketika memaksakan reservasi system-reserved karena dapat
menyebabkan layanan sistem yang terpenting mengalami CPU starvation, OOM killed, atau tidak
dapat melakukan fork pada Node. Kami menyarankan untuk memaksakan system-reserved hanya
jika pengguna telah melakukan profiling sebaik mungkin pada Node mereka untuk
mendapatkan estimasi yang akurat dan percaya diri terhadap kemampuan mereka untuk
memulihkan sistem ketika ada grup yang terkena OOM killed.
- Untuk memulai, paksakan
Allocatablepada Pod. - Ketika monitoring dan alerting telah cukup dilakukan untuk memonitor daemon
dari sistem Kubernetes, usahakan untuk memaksakan
kube-reservedberdasarkan penggunakan heuristik. - Jika benar-benar diperlukan, paksakan
system-reservedsecara bertahap.
Sumber daya yang diperlukan oleh daemon sistem Kubernetes dapat tumbuh seiring waktu dengan
adanya penambahan fitur-fitur baru. Proyek Kubernetes akan berusaha untuk menurunkan penggunaan sumber daya
dari daemon sistem Node, tetapi belum menjadi prioritas untuk saat ini.
Kamu dapat berekspektasi bahwa fitur kapasitas Allocatable ini akan dihapus pada versi yang akan datang.
Contoh Skenario
Berikut ini merupakan contoh yang menggambarkan komputasi Allocatable pada Node:
- Node memiliki 16 CPU, memori sebesar 32Gi, dan penyimpanan sebesar 100Gi.
--kube-reserveddiatur menjadicpu=1,memory=2Gi,ephemeral-storage=1Gi--system-reserveddiatur menjadicpu=500m,memory=1Gi,ephemeral-storage=1Gi--eviction-harddiatur menjadimemory.available<500Mi,nodefs.available<10%
Dalam skenario ini, Allocatable akan menjadi 14.5 CPU, memori 28.5Gi, dan penyimpanan
lokal 88Gi.
Penjadwal memastikan bahwa semua Pod yang berjalan pada Node ini secara total tidak meminta memori melebihi
28.5Gi dan tidak menggunakan penyimpanan lokal melebihi 88Gi.
Pengusiran Pod akan dilakukan kubelet ketika penggunaan memori keseluruhan oleh Pod telah melebihi 28.5Gi,
atau jika penggunaan penyimpanan keseluruhan telah melebihi 88Gi. Jika semua proses pada Node mengonsumsi
CPU sebanyak-banyaknya, Pod-Pod tidak dapat mengonsumsi lebih dari 14.5 CPU.
Jika kube-reserved dan/atau system-reserved tidak dipaksakan dan daemon sistem
melebihi reservasi mereka, maka kubelet akan mengusir Pod ketika penggunaan memori pada Node
melebihi 31.5Gi atau penggunaan penyimpanan melebihi 90Gi.
6 - Membagi sebuah Klaster dengan Namespace
Laman ini menunjukkan bagaimana cara melihat, menggunakan dan menghapus namespaces. Laman ini juga menunjukkan bagaimana cara menggunakan Namespace Kubernetes namespaces untuk membagi klaster kamu.
Sebelum kamu memulai
- Memiliki Klaster Kubernetes.
- Memiliki pemahaman dasar Pod, Service, dan Deployment dalam Kubernetes.
Melihat Namespace
- Untuk melihat Namespace yang ada saat ini pada sebuah klaster anda bisa menggunakan:
kubectl get namespaces
NAME STATUS AGE
default Active 11d
kube-system Active 11d
kube-public Active 11d
Kubernetes mulai dengan tiga Namespace pertama:
defaultNamespace bawaan untuk objek-objek yang belum terkait dengan Namespace lainkube-systemNamespace untuk objek-objek yang dibuat oleh sistem Kuberneteskube-publicNamespace ini dibuat secara otomatis dan dapat dibaca oleh seluruh pengguna (termasuk yang tidak terotentikasi). Namespace ini sering dicadangkan untuk kepentingan klaster, untuk kasus dimana beberapa sumber daya seharusnya dapat terlihat dan dapat terlihat secara publik di seluruh klaster. Aspek publik pada Namespace ini hanya sebuah konvensi bukan suatu kebutuhan.
Kamu bisa mendapat ringkasan Namespace tertentu dengan menggunakan:
kubectl get namespaces <name>
Atau kamu bisa mendapatkan informasi detail menggunakan:
kubectl describe namespaces <name>
Name: default
Labels: <none>
Annotations: <none>
Status: Active
No resource quota.
Resource Limits
Type Resource Min Max Default
---- -------- --- --- ---
Container cpu - - 100m
Sebagai catatan, detail diatas menunjukkan baik kuota sumber daya (jika ada) dan juga jangkauan batas sumber daya.
Kuota sumber daya melacak penggunaan total sumber daya didalam Namespace dan mengijinkan operator-operator klaster mendefinisikan batas atas penggunaan sumber daya yang dapat di gunakan sebuah Namespace.
Jangkauan batas mendefinisikan pertimbangan min/maks jumlah sumber daya yang dapat di gunakan oleh sebuah entitas dalam sebuah Namespace.
Lihatlah Kontrol Admisi: Rentang Batas
Sebuah Namespace dapat berada dalam salah satu dari dua buah fase:
ActiveNamespace sedang digunakanTerminatingNamespace sedang dihapus dan tidak dapat digunakan untuk objek-objek baru
Lihat dokumentasi desain untuk detil lebih lanjut.
Membuat sebuah Namespace baru
Catatan: Hindari membuat Namespace dengan awalankube-, karena awalan ini dicadangkan untuk Namespace dari sistem Kubernetes.
-
Buat berkas YAML baru dengan nama
my-namespace.yamldengan isi berikut ini:apiVersion: v1 kind: Namespace metadata: name: <masukkan-nama-namespace-disini>Then run:
kubectl create -f ./my-namespace.yaml -
Sebagai alternatif, kamu bisa membuat Namespace menggunakan perintah dibawah ini:
kubectl create namespace <masukkan-nama-namespace-disini>
Nama Namespace kamu harus merupakan Label DNS yang valid.
Ada kolom opsional finalizers, yang memungkinkan observables untuk membersihkan sumber daya ketika Namespace dihapus. Ingat bahwa jika kamu memberikan finalizer yang tidak ada, Namespace akan dibuat tapi akan berhenti pada status Terminating jika pengguna mencoba untuk menghapusnya.
Informasi lebih lanjut mengenai finalizers bisa dibaca pada dokumentasi desain dari Namespace.
Menghapus Namespace
Hapus Namespace dengan
kubectl delete namespaces <insert-some-namespace-name>
Peringatan: Ini akan menghapus semua hal yang ada dalam Namespace!
Proses penghapusan ini asinkron, jadi untuk beberapa waktu kamu akan melihat Namespace dalam status Terminating.
Membagi klaster kamu menggunakan Namespace Kubernetes
-
Pahami Namespace bawaan
Secara bawaan, sebuah klaster Kubernetes akan membuat Namespace bawaan ketika menyediakan klaster untuk menampung Pod, Service, dan Deployment yang digunakan oleh klaster.
Dengan asumsi kamu memiliki klaster baru, kamu bisa mengecek Namespace yang tersedia dengan melakukan hal berikut:
kubectl get namespacesNAME STATUS AGE default Active 13m -
Membuat Namespace baru
Untuk latihan ini, kita akan membuat dua Namespace Kubernetes tambahan untuk menyimpan konten kita
Dalam sebuah skenario dimana sebuah organisasi menggunakan klaster Kubernetes yang digunakan bersama untuk penggunaan pengembangan dan produksi:
Tim pengembang ingin mengelola ruang di dalam klaster dimana mereka bisa melihat daftar Pod, Service, dan Deployment yang digunakan untuk membangun dan menjalankan apliksi mereka. Di ruang ini sumber daya akan datang dan pergi, dan pembatasan yang tidak ketat mengenai siapa yang bisa atau tidak bisa memodifikasi sumber daya untuk mendukung pengembangan secara gesit (agile).
Tim operasi ingin mengelola ruang didalam klaster dimana mereka bisa memaksakan prosedur ketat mengenai siapa yang bisa atau tidak bisa melakukan manipulasi pada kumpulan Pod, Layanan, dan Deployment yang berjalan pada situs produksi.
Satu pola yang bisa diikuti organisasi ini adalah dengan membagi klaster Kubernetes menjadi dua Namespace:
developmentdanproductionMari kita buat dua Namespace untuk menyimpan hasil kerja kita.
Buat Namespace
developmentmenggunakan kubectl:kubectl create -f https://k8s.io/examples/admin/namespace-dev.jsonKemudian mari kita buat Namespace
productionmenggunakan kubectl:kubectl create -f https://k8s.io/examples/admin/namespace-prod.jsonUntuk memastikan apa yang kita lakukan benar, lihat seluruh Namespace dalam klaster.
kubectl get namespaces --show-labelsNAME STATUS AGE LABELS default Active 32m <none> development Active 29s name=development production Active 23s name=production -
Buat pod pada setiap Namespace
Sebuah Namespace Kubernetes memberikan batasan untuk Pod, Service, dan Deployment dalam klaster.
Pengguna yang berinteraksi dengan salah satu Namespace tidak melihat konten di dalam Namespace lain
Untuk menunjukkan hal ini, mari kita jalankan Deployment dan Pod sederhana di dalam Namespace
development.kubectl create deployment snowflake --image=k8s.gcr.io/serve_hostname -n=development kubectl scale deployment snowflake --replicas=2 -n=developmentKita baru aja membuat sebuah Deployment yang memiliki ukuran replika dua yang menjalankan Pod dengan nama
snowflakedengan sebuah Container dasar yang hanya melayani hostname.kubectl get deployment -n=developmentNAME READY UP-TO-DATE AVAILABLE AGE snowflake 2/2 2 2 2mkubectl get pods -l app=snowflake -n=developmentNAME READY STATUS RESTARTS AGE snowflake-3968820950-9dgr8 1/1 Running 0 2m snowflake-3968820950-vgc4n 1/1 Running 0 2mDan ini merupakan sesuatu yang bagus, dimana pengembang bisa melakukan hal yang ingin mereka lakukan tanpa harus khawatir hal itu akan mempengaruhi konten pada namespace
production.Mari kita pindah ke Namespace
productiondan menujukkan bagaimana sumber daya di satu Namespace disembunyikan dari yang lainNamespace
productionseharusnya kosong, dan perintah berikut ini seharusnya tidak menghasilkan apapun.kubectl get deployment -n=production kubectl get pods -n=productionProductionNamespace ingin menjalankancattle, mari kita buat beberapa Podcattle.kubectl create deployment cattle --image=k8s.gcr.io/serve_hostname -n=production kubectl scale deployment cattle --replicas=5 -n=production kubectl get deployment -n=productionNAME READY UP-TO-DATE AVAILABLE AGE cattle 5/5 5 5 10skubectl get pods -l app=cattle -n=productionNAME READY STATUS RESTARTS AGE cattle-2263376956-41xy6 1/1 Running 0 34s cattle-2263376956-kw466 1/1 Running 0 34s cattle-2263376956-n4v97 1/1 Running 0 34s cattle-2263376956-p5p3i 1/1 Running 0 34s cattle-2263376956-sxpth 1/1 Running 0 34s
Sampai sini, seharusnya sudah jelas bahwa sumber daya yang dibuat pengguna pada sebuah Namespace disembunyikan dari Namespace lainnya.
Seiring dengan evolusi dukungan kebijakan di Kubernetes, kami akan memperluas skenario ini untuk menunjukkan bagaimana kamu bisa menyediakan aturan otorisasi yang berbeda untuk tiap Namespace.
Memahami motivasi penggunaan Namespace
Sebuah klaster tunggal umumnya bisa memenuhi kebutuhan pengguna yang berbeda atau kelompok pengguna (itulah sebabnya disebut 'komunitas pengguna').
Namespace Kubernetes membantu proyek-proyek, tim-tim dan pelanggan yang berbeda untuk berbagi klaster Kubernetes.
Ini dilakukan dengan menyediakan hal berikut:
- Cakupan untuk Names.
- Sebuah mekanisme untuk memasang otorisasi dan kebijakan untuk bagian dari klaster.
Penggunaan Namespace berbeda merupakan hal opsional.
Tiap komunitas pengguna ingin bisa bekerja secara terisolasi dari komunitas lainnya.
Tiap komunitas pengguna memiliki hal berikut sendiri:
- sumber daya (Pod, Service, ReplicationController, dll.)
- kebijakan (siapa yang bisa atau tidak bisa melakukan hal tertentu dalam komunitasnya)
- batasan (komunitas ini diberi kuota sekian, dll.)
Seorang operator klaster dapat membuat sebuah Namespace untuk tiap komunitas user yang unik.
Namespace tersebut memberikan cakupan yang unik untuk:
- penamaan sumber daya (untuk menghindari benturan penamaan dasar)
- pendelegasian otoritas pengelolaan untuk pengguna yang dapat dipercaya
- kemampuan untuk membatasi konsumsi sumber daya komunitas
Contoh penggunaan mencakup
- Sebagai operator klaster, aku ingin mendukung beberapa komunitas pengguna dalam sebuah klaster.
- Sebagai operator klaster, aku ingin mendelegasikan otoritas untuk mempartisi klaster ke pengguna terpercaya di komunitasnya.
- Sebagai operator klaster, aku ingin membatasi jumlah sumber daya yang bisa dikonsumsi komunitas dalam rangka membatasi dampak ke komunitas lain yang menggunakan klaster yang sama.
- Sebagai pengguna klaster, aku ingin berinteraksi dengan sumber daya yang berkaitan dengan komunitas pengguna saya secara terisolasi dari apa yang dilakukan komunitas lain di klaster yang sama.
Memahami Namespace dan DNS
Ketika kamu membuat sebuah Service, akan terbentuk entri DNS untuk Service tersebut.
Entri DNS ini dalam bentuk <service-name>.<namespace-name>.svc.cluster.local, yang berarti jika sebuah Container hanya menggunakan <service-name> maka dia akan me-resolve ke layanan yang lokal dalam Namespace yang sama. Ini berguna untuk menggunakan konfigurasi yang sama pada Namespace yang berbeda seperti Development, Staging dan Production. Jika kami ingin menjangkau antar Namespace, kamu harus menggunakan fully qualified domain name (FQDN).
Selanjutnya
- Pelajari lebih lanjut mengenai pengaturan preferensi Namespace.
- Pelajari lebih lanjut mengenai pengaturan namespace untuk sebuah permintaan
- Baca desain Namespace.
7 - Mengatur Control Plane Kubernetes dengan Ketersediaan Tinggi (High-Availability)
Kubernetes v1.5 [alpha]
Kamu dapat mereplikasi control plane Kubernetes dalam skrip kube-up atau kube-down untuk Google Compute Engine (GCE).
Dokumen ini menjelaskan cara menggunakan skrip kube-up/down untuk mengelola control plane dengan ketersedian tinggi atau high_availability (HA) dan bagaimana control plane HA diimplementasikan untuk digunakan dalam GCE.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu belum memiliki klaster, kamu dapat membuatnya dengan menggunakan minikube, atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Untuk melihat versi, tekankubectl version.
Memulai klaster yang kompatibel dengan HA
Untuk membuat klaster yang kompatibel dengan HA, kamu harus mengatur tanda ini pada skrip kube-up:
-
MULTIZONE=true- untuk mencegah penghapusan replika control plane kubelet dari zona yang berbeda dengan zona bawaan server. Ini diperlukan jika kamu ingin menjalankan replika control plane pada zona berbeda, dimana hal ini disarankan. -
ENABLE_ETCD_QUORUM_READ=true- untuk memastikan bahwa pembacaan dari semua server API akan mengembalikan data terbaru. Jikatrue, bacaan akan diarahkan ke replika pemimpin dari etcd. Menetapkan nilai ini menjaditruebersifat opsional: pembacaan akan lebih dapat diandalkan tetapi juga akan menjadi lebih lambat.
Sebagai pilihan, kamu dapat menentukan zona GCE tempat dimana replika control plane pertama akan dibuat. Atur tanda berikut:
KUBE_GCE_ZONE=zone- zona tempat di mana replika control plane pertama akan berjalan.
Berikut ini contoh perintah untuk mengatur klaster yang kompatibel dengan HA pada zona GCE europe-west1-b:
MULTIZONE=true KUBE_GCE_ZONE=europe-west1-b ENABLE_ETCD_QUORUM_READS=true ./cluster/kube-up.sh
Perhatikan bahwa perintah di atas digunakan untuk membuat klaster dengan sebuah control plane; Namun, kamu bisa menambahkan replika control plane baru ke klaster dengan perintah berikutnya.
Menambahkan replika control plane yang baru
Setelah kamu membuat klaster yang kompatibel dengan HA, kamu bisa menambahkan replika control plane ke sana.
Kamu bisa menambahkan replika control plane dengan menggunakan skrip kube-up dengan tanda berikut ini:
-
KUBE_REPLICATE_EXISTING_MASTER=true- untuk membuat replika dari control plane yang sudah ada. -
KUBE_GCE_ZONE=zone- zona di mana replika control plane itu berjalan. Region ini harus sama dengan region dari zona replika yang lain.
Kamu tidak perlu mengatur tanda MULTIZONE atau ENABLE_ETCD_QUORUM_READS,
karena tanda itu diturunkan pada saat kamu memulai klaster yang kompatible dengan HA.
Berikut ini contoh perintah untuk mereplikasi control plane pada klaster sebelumnya yang kompatibel dengan HA:
KUBE_GCE_ZONE=europe-west1-c KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
Menghapus replika control plane
Kamu dapat menghapus replika control plane dari klaster HA dengan menggunakan skrip kube-down dengan tanda berikut:
-
KUBE_DELETE_NODES=false- untuk mencegah penghapusan kubelet. -
KUBE_GCE_ZONE=zone- zona di mana replika control plane akan dihapus. -
KUBE_REPLICA_NAME=replica_name- (opsional) nama replika control plane yang akan dihapus. Jika kosong: replika mana saja dari zona yang diberikan akan dihapus.
Berikut ini contoh perintah untuk menghapus replika control plane dari klaster HA yang sudah ada sebelumnya:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=europe-west1-c ./cluster/kube-down.sh
Mengatasi replika control plane yang gagal
Jika salah satu replika control plane di klaster HA kamu gagal, praktek terbaik adalah menghapus replika dari klaster kamu dan menambahkan replika baru pada zona yang sama. Berikut ini contoh perintah yang menunjukkan proses tersebut:
- Menghapus replika yang gagal:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=replica_zone KUBE_REPLICA_NAME=replica_name ./cluster/kube-down.sh
- Menambahkan replika baru untuk menggantikan replika yang lama
KUBE_GCE_ZONE=replica-zone KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
Praktek terbaik untuk mereplikasi control plane untuk klaster HA
-
Usahakan untuk menempatkan replika control plane pada zona yang berbeda. Pada saat terjadi kegagalan zona, semua control plane yang ditempatkan dalam zona tersebut akan gagal pula. Untuk bertahan dari kegagalan pada sebuah zona, tempatkan juga Node pada beberapa zona yang lain (Lihatlah multi-zona untuk lebih detail).
-
Jangan gunakan klaster dengan dua replika control plane. Konsensus pada klaster dengan dua replika membutuhkan kedua replika tersebut berjalan pada saat mengubah keadaan yang persisten. Akibatnya, kedua replika tersebut diperlukan dan kegagalan salah satu replika mana pun mengubah klaster dalam status kegagalan mayoritas. Dengan demikian klaster dengan dua replika lebih buruk, dalam hal HA, daripada klaster dengan replika tunggal.
-
Ketika kamu menambahkan sebuah replika control plane, status klaster (etcd) disalin ke sebuah instance baru. Jika klaster itu besar, mungkin butuh waktu yang lama untuk menduplikasi keadaannya. Operasi ini dapat dipercepat dengan memigrasi direktori data etcd, seperti yang dijelaskan di sini (Kami sedang mempertimbangkan untuk menambahkan dukungan untuk migrasi direktori data etcd di masa mendatang).
Catatan implementasi
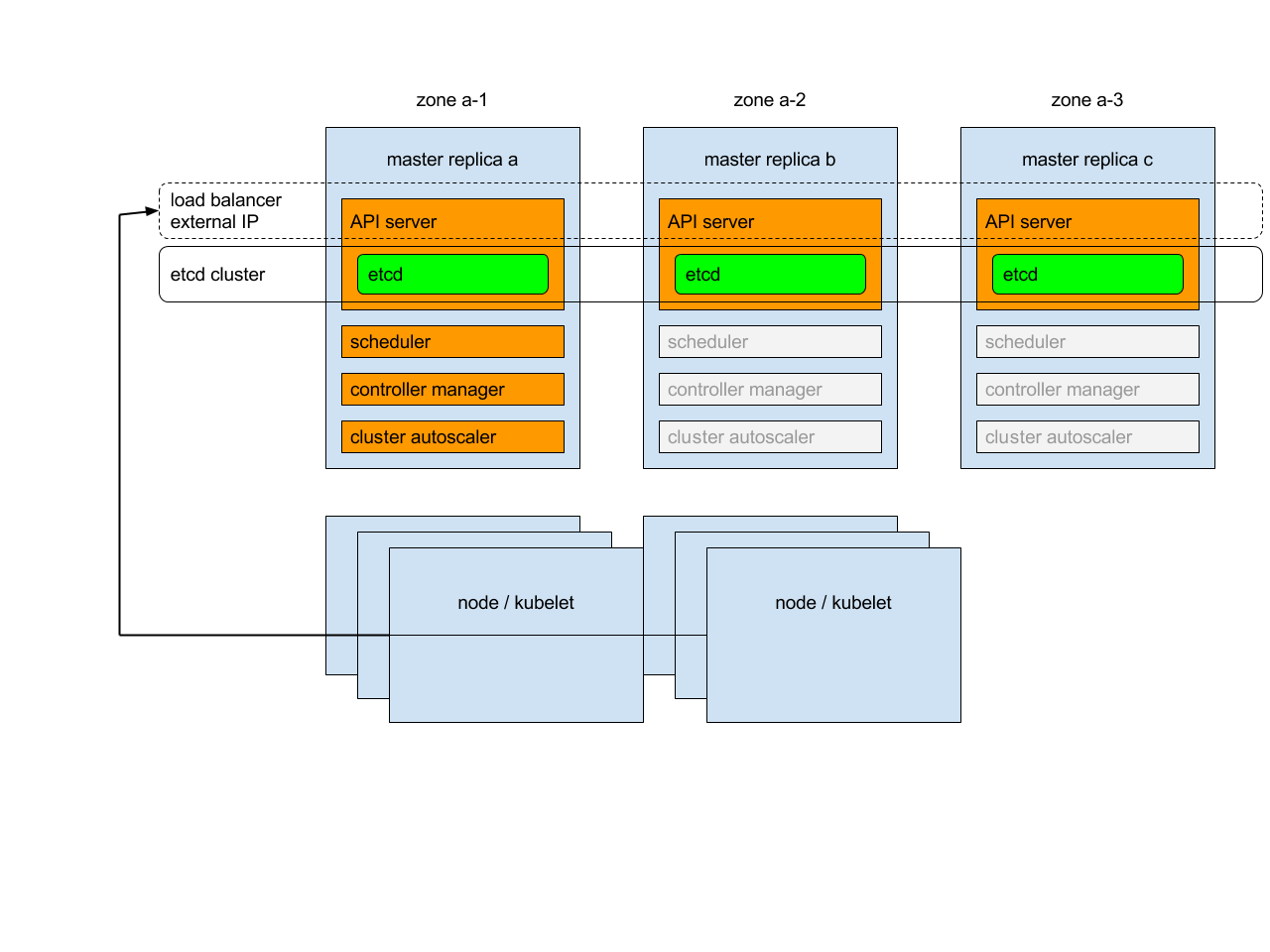
Ikhtisar
Setiap replika control plane akan menjalankan komponen berikut dalam mode berikut:
-
instance etcd: semua instance akan dikelompokkan bersama menggunakan konsensus;
-
server API : setiap server akan berbicara dengan lokal etcd - semua server API pada cluster akan tersedia;
-
pengontrol (controller), penjadwal (scheduler), dan scaler klaster automatis: akan menggunakan mekanisme sewa - dimana hanya satu instance dari masing-masing mereka yang akan aktif dalam klaster;
-
manajer tambahan (add-on): setiap manajer akan bekerja secara independen untuk mencoba menjaga tambahan dalam sinkronisasi.
Selain itu, akan ada penyeimbang beban (load balancer) di depan server API yang akan mengarahkan lalu lintas eksternal dan internal menuju mereka.
Penyeimbang Beban
Saat memulai replika control plane kedua, penyeimbang beban yang berisi dua replika akan dibuat dan alamat IP dari replika pertama akan dipromosikan ke alamat IP penyeimbang beban. Demikian pula, setelah penghapusan replika control plane kedua yang dimulai dari paling akhir, penyeimbang beban akan dihapus dan alamat IP-nya akan diberikan ke replika terakhir yang ada. Mohon perhatikan bahwa pembuatan dan penghapusan penyeimbang beban adalah operasi yang rumit dan mungkin perlu beberapa waktu (~20 menit) untuk dipropagasikan.
Service control plane & kubelet
Daripada sistem mencoba untuk menjaga daftar terbaru dari apiserver Kubernetes yang ada dalam Service Kubernetes, sistem akan mengarahkan semua lalu lintas ke IP eksternal:
-
dalam klaster dengan satu control plane, IP diarahkan ke control plane tunggal.
-
dalam klaster dengan multiple control plane, IP diarahkan ke penyeimbang beban yang ada di depan control plane.
Demikian pula, IP eksternal akan digunakan oleh kubelet untuk berkomunikasi dengan control plane.
Sertifikat control plane
Kubernetes menghasilkan sertifikat TLS control plane untuk IP publik eksternal dan IP lokal untuk setiap replika. Tidak ada sertifikat untuk IP publik sementara (ephemeral) dari replika; Untuk mengakses replika melalui IP publik sementara, kamu harus melewatkan verifikasi TLS.
Pengklasteran etcd
Untuk mengizinkan pengelompokkan etcd, porta yang diperlukan untuk berkomunikasi antara instance etcd akan dibuka (untuk komunikasi dalam klaster). Untuk membuat penyebaran itu aman, komunikasi antara instance etcd diotorisasi menggunakan SSL.
Bacaan tambahan
8 - Menggunakan sysctl dalam Sebuah Klaster Kubernetes
Kubernetes v1.12 [beta]
Dokumen ini menjelaskan tentang cara mengonfigurasi dan menggunakan parameter kernel dalam sebuah klaster Kubernetes dengan menggunakan antarmuka sysctl.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu belum memiliki klaster, kamu dapat membuatnya dengan menggunakan minikube, atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Untuk melihat versi, tekankubectl version.
Melihat Daftar Semua Parameter Sysctl
Dalam Linux, antarmuka sysctl memungkinkan administrator untuk memodifikasi kernel
parameter pada runtime. Parameter tersedia melalui sistem file virtual dari proses /proc/sys/.
Parameter mencakup berbagai subsistem seperti:
- kernel (dengan prefiks umum:
kernel.) - networking (dengan prefiks umum:
net.) - virtual memory (dengan prefiks umum:
vm.) - MDADM (dengan prefiks umum:
dev.) - subsistem yang lainnya dideskripsikan pada dokumentasi Kernel.
Untuk mendapatkan daftar semua parameter, kamu bisa menjalankan perintah:
sudo sysctl -a
Mengaktifkan Sysctl Unsafe
Sysctl dikelompokkan menjadi sysctl safe dan sysctl unsafe. Sebagai tambahan untuk pengaturan Namespace yang benar, sebuah sysctl safe harus diisolasikan dengan benar diantara Pod dalam Node yang sama. Hal ini berarti mengatur sysctl safe dalam satu Pod:
- tidak boleh mempengaruhi Pod lain dalam Node
- tidak boleh membahayakan kesehatan dari Node
- tidak mengizinkan untuk mendapatkan sumber daya CPU atau memori di luar batas sumber daya dari sebuah Pod.
Sejauh ini, sebagian besar sysctl yang diatur sebagai Namespace belum tentu dianggap sysctl safe. Sysctl berikut ini didukung dalam kelompok safe:
kernel.shm_rmid_forced,net.ipv4.ip_local_port_range,net.ipv4.tcp_syncookies,net.ipv4.ping_group_range(sejak Kubernetes 1.18).
Catatan:Contoh
net.ipv4.tcp_syncookiesbukan merupakan Namespace pada kernel Linux versi 4.4 atau lebih rendah.Daftar ini akan terus dikembangkan dalam versi Kubernetes berikutnya ketika kubelet mendukung mekanisme isolasi yang lebih baik.
Semua sysctl safe diaktifkan secara bawaan.
Semua sysctl unsafe dinon-aktifkan secara bawaan dan harus diizinkan secara manual oleh administrator klaster untuk setiap Node. Pod dengan sysctl unsafe yang dinon-aktifkan akan dijadwalkan, tetapi akan gagal untuk dijalankan.
Dengan mengingat peringatan di atas, administrator klaster dapat mengizinkan sysctl unsafe tertentu untuk situasi yang sangat spesial seperti pada saat kinerja tinggi atau penyetelan aplikasi secara real-time. Unsafe syctl diaktifkan Node demi Node melalui flag pada kubelet; sebagai contoh:
kubelet --allowed-unsafe-sysctls \ 'kernel.msg*,net.core.somaxconn' ...Untuk Minikube, ini dapat dilakukan melalui flag
extra-config:minikube start --extra-config="kubelet.allowed-unsafe-sysctls=kernel.msg*,net.core.somaxconn"...Hanya sysctl yang diatur sebagai Namespace dapat diaktifkan dengan cara ini.
Mnegatur Sysctl untuk Pod
Sejumlah sysctl adalah diatur sebagai Namespace dalam Kernel Linux hari ini. Ini berarti mereka dapat diatur secara independen untuk setiap Pod dalam sebuah Node. Hanya sysctl dengan Namespace yang dapat dikonfigurasi melalui Pod securityContext dalam Kubernetes.
Sysctl berikut dikenal sebagai Namespace. Daftar ini dapat berubah pada versi kernel Linux yang akan datang.
kernel.shm*,kernel.msg*,kernel.sem,fs.mqueue.*,- Parameter dibawah
net.*dapat diatur sebagai Namespace dari container networking Namun, ada beberapa perkecualian (sepertinet.netfilter.nf_conntrack_maxdannet.netfilter.nf_conntrack_expect_maxyang dapat diatur dalam Namespace container networking padahal bukan merupakan Namespace).Sysctl tanpa Namespace disebut dengan sysctl node-level. Jika kamu perlu mengatur mereka, kamu harus secara manual mengonfigurasi mereka pada sistem operasi setiap Node, atau dengan menggunakan DaemonSet melalui Container yang berwenang.
Gunakan securityContext dari Pod untuk mengonfigurasi sysctl Namespace. securityContext berlaku untuk semua Container dalam Pod yang sama.
Contoh ini menggunakan securityContext dari Pod untuk mengatur sebuah sysctl safe
kernel.shm_rmid_forced, dan dua buah sysctl unsafenet.core.somaxconndankernel.msgmax. Tidak ada perbedaan antara sysctl safe dan sysctl unsafe dalam spesifikasi tersebut.Peringatan: Hanya modifikasi parameter sysctl setelah kamu memahami efeknya, untuk menghindari gangguan pada kestabilan sistem operasi kamu.apiVersion: v1 kind: Pod metadata: name: sysctl-example spec: securityContext: sysctls: - name: kernel.shm_rmid_forced value: "0" - name: net.core.somaxconn value: "1024" - name: kernel.msgmax value: "65536" ...Peringatan: Karena sifat alami dari sysctl unsafe, penggunaan sysctl unsafe merupakan resiko kamu sendiri dan dapat menyebabkan masalah parah seperti perilaku yang salah pada Container, kekurangan sumber daya, atau kerusakan total dari Node.Merupakan sebuah praktik yang baik untuk mempertimbangkan Node dengan pengaturan sysctl khusus sebagai Node yang tercemar (tainted) dalam sebuah cluster, dan hanya menjadwalkan Pod yang membutuhkan pengaturan sysctl. Sangat disarankan untuk menggunakan Kubernetes fitur taints and toleration untuk mengimplementasikannya.
Pod dengan sysctl unsafe akan gagal diluncurkan pada sembarang Node yang belum mengaktifkan kedua sysctl unsafe secara eksplisit. Seperti halnya sysctl node-level sangat disarankan untuk menggunakan fitur taints and toleration atau pencemaran dalam Node untuk Pod dalam Node yang tepat.
PodSecurityPolicy
Kamu selanjutnya dapat mengontrol sysctl mana saja yang dapat diatur dalam Pod dengan menentukan daftar sysctl atau pola (pattern) sysctl dalam
forbiddenSysctlsdan/atau fieldallowedUnsafeSysctlsdari PodSecurityPolicy. Pola sysctl diakhiri dengan karakter*, sepertikernel.*. Karakter*saja akan mencakup semua sysctl.Secara bawaan, semua sysctl safe diizinkan.
Kedua
forbiddenSysctlsdanallowedUnsafeSysctlsmerupakan daftar dari nama sysctl atau pola sysctl yang polos (yang diakhiri dengan karakter*). Karakter*saja berarti sesuai dengan semua sysctl.Field
forbiddenSysctlstidak memasukkan sysctl tertentu. Kamu dapat melarang kombinasi sysctl safe dan sysctl unsafe dalam daftar tersebut. Untuk melarang pengaturan sysctl, hanya gunakan*saja.Jika kamu menyebutkan sysctl unsafe pada field
allowedUnsafeSysctlsdan tidak ada pada fieldforbiddenSysctls, maka sysctl dapat digunakan pada Pod dengan menggunakan PodSecurityPolicy ini. Untuk mengizinkan semua sysctl unsafe diatur dalam PodSecurityPolicy, gunakan karakter*saja.Jangan mengonfigurasi kedua field ini sampai tumpang tindih, dimana sysctl yang diberikan akan diperbolehkan dan dilarang sekaligus.
Peringatan: Jika kamu mengizinkan sysctl unsafe melalui fieldallowUnsafeSysctlspada PodSecurityPolicy, Pod apa pun yang menggunakan sysctl seperti itu akan gagal dimulai jika sysctl unsafe tidak diperbolehkan dalam flag kubelet--allowed-unsafe-sysctlspada Node tersebut.Ini merupakan contoh sysctl unsafe yang diawali dengan
kernel.msgyang diperbolehkan dan sysctlkernel.shm_rmid_forcedyang dilarang.apiVersion: policy/v1beta1 kind: PodSecurityPolicy metadata: name: sysctl-psp spec: allowedUnsafeSysctls: - kernel.msg* forbiddenSysctls: - kernel.shm_rmid_forced ...
9 - Mengoperasikan klaster etcd untuk Kubernetes
etcd adalah penyimpanan key value konsisten yang digunakan sebagai penyimpanan data klaster Kubernetes.
Selalu perhatikan mekanisme untuk mem-backup data etcd pada klaster Kubernetes kamu. Untuk informasi lebih lanjut tentang etcd, lihat dokumentasi etcd.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu belum memiliki klaster, kamu dapat membuatnya dengan menggunakan minikube, atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Untuk melihat versi, tekankubectl version.
Prerequisites
-
Jalankan etcd sebagai klaster dimana anggotanya berjumlah ganjil.
-
Etcd adalah sistem terdistribusi berbasis leader. Pastikan leader secara berkala mengirimkan heartbeat dengan tepat waktu ke semua pengikutnya untuk menjaga kestabilan klaster.
-
Pastikan tidak terjadi kekurangan sumber daya.
Kinerja dan stabilitas dari klaster sensitif terhadap jaringan dan IO disk. Kekurangan sumber daya apa pun dapat menyebabkan timeout dari heartbeat, yang menyebabkan ketidakstabilan klaster. Etcd yang tidak stabil mengindikasikan bahwa tidak ada leader yang terpilih. Dalam keadaan seperti itu, sebuah klaster tidak dapat membuat perubahan apa pun ke kondisi saat ini, yang menyebabkan tidak ada Pod baru yang dapat dijadwalkan.
-
Menjaga kestabilan klaster etcd sangat penting untuk stabilitas klaster Kubernetes. Karenanya, jalankan klaster etcd pada mesin khusus atau lingkungan terisolasi untuk persyaratan sumber daya terjamin.
-
Versi minimum yang disarankan untuk etcd yang dijalankan dalam lingkungan produksi adalah
3.2.10+.
Persyaratan sumber daya
Mengoperasikan etcd dengan sumber daya terbatas hanya cocok untuk tujuan pengujian. Untuk peluncuran dalam lingkungan produksi, diperlukan konfigurasi perangkat keras lanjutan. Sebelum meluncurkan etcd dalam produksi, lihat dokumentasi referensi persyaratan sumber daya.
Memulai Klaster etcd
Bagian ini mencakup bagaimana memulai klaster etcd dalam Node tunggal dan Node multipel.
Klaster etcd dalam Node tunggal
Gunakan Klaster etcd Node tunggal hanya untuk tujuan pengujian
-
Jalankan perintah berikut ini:
./etcd --listen-client-urls=http://$PRIVATE_IP:2379 --advertise-client-urls=http://$PRIVATE_IP:2379 -
Start server API Kubernetes dengan flag
--etcd-servers=$PRIVATE_IP:2379.Ganti
PRIVATE_IPdengan IP klien etcd kamu.
Klaster etcd dengan Node multipel
Untuk daya tahan dan ketersediaan tinggi, jalankan etcd sebagai klaster dengan Node multipel dalam lingkungan produksi dan cadangkan secara berkala. Sebuah klaster dengan lima anggota direkomendasikan dalam lingkungan produksi. Untuk informasi lebih lanjut, lihat Dokumentasi FAQ.
Mengkonfigurasi klaster etcd baik dengan informasi anggota statis atau dengan penemuan dinamis. Untuk informasi lebih lanjut tentang pengklasteran, lihat Dokumentasi pengklasteran etcd.
Sebagai contoh, tinjau sebuah klaster etcd dengan lima anggota yang berjalan dengan URL klien berikut: http://$IP1:2379, http://$IP2:2379, http://$IP3:2379, http://$IP4:2379, dan http://$IP5:2379. Untuk memulai server API Kubernetes:
-
Jalankan perintah berikut ini:
./etcd --listen-client-urls=http://$IP1:2379, http://$IP2:2379, http://$IP3:2379, http://$IP4:2379, http://$IP5:2379 --advertise-client-urls=http://$IP1:2379, http://$IP2:2379, http://$IP3:2379, http://$IP4:2379, http://$IP5:2379 -
Start server Kubernetes API dengan flag
--etcd-servers=$IP1:2379, $IP2:2379, $IP3:2379, $IP4:2379, $IP5:2379.Ganti
IPdengan alamat IP klien kamu.
Klaster etcd dengan Node multipel dengan load balancer
Untuk menjalankan penyeimbangan beban (load balancing) untuk klaster etcd:
- Siapkan sebuah klaster etcd.
- Konfigurasikan sebuah load balancer di depan klaster etcd.
Sebagai contoh, anggap saja alamat load balancer adalah
$LB. - Mulai Server API Kubernetes dengan flag
--etcd-servers=$LB:2379.
Mengamankan klaster etcd
Akses ke etcd setara dengan izin root pada klaster sehingga idealnya hanya server API yang memiliki akses ke etcd. Dengan pertimbangan sensitivitas data, disarankan untuk memberikan izin hanya kepada Node-Node yang membutuhkan akses ke klaster etcd.
Untuk mengamankan etcd, tetapkan aturan firewall atau gunakan fitur keamanan yang disediakan oleh etcd. Fitur keamanan etcd tergantung pada Infrastruktur Kunci Publik / Public Key Infrastructure (PKI) x509. Untuk memulai, buat saluran komunikasi yang aman dengan menghasilkan pasangan kunci dan sertifikat. Sebagai contoh, gunakan pasangan kunci peer.key dan peer.cert untuk mengamankan komunikasi antara anggota etcd, dan client.key dan client.cert untuk mengamankan komunikasi antara etcd dan kliennya. Lihat contoh skrip yang disediakan oleh proyek etcd untuk menghasilkan pasangan kunci dan berkas CA untuk otentikasi klien.
Mengamankan komunikasi
Untuk mengonfigurasi etcd dengan secure peer communication, tentukan flag --peer-key-file=peer.key dan --peer-cert-file=peer.cert, dan gunakan https sebagai skema URL.
Demikian pula, untuk mengonfigurasi etcd dengan secure client communication, tentukan flag --key-file=k8sclient.key dan --cert-file=k8sclient.cert, dan gunakan https sebagai skema URL.
Membatasi akses klaster etcd
Setelah konfigurasi komunikasi aman, batasi akses klaster etcd hanya ke server API Kubernetes. Gunakan otentikasi TLS untuk melakukannya.
Sebagai contoh, anggap pasangan kunci k8sclient.key dan k8sclient.cert dipercaya oleh CA etcd.ca. Ketika etcd dikonfigurasi dengan --client-cert-auth bersama dengan TLS, etcd memverifikasi sertifikat dari klien dengan menggunakan CA dari sistem atau CA yang dilewati oleh flag --trusted-ca-file. Menentukan flag --client-cert-auth=true dan --trusted-ca-file=etcd.ca akan membatasi akses kepada klien yang mempunyai sertifikat k8sclient.cert.
Setelah etcd dikonfigurasi dengan benar, hanya klien dengan sertifikat yang valid dapat mengaksesnya. Untuk memberikan akses kepada server Kubernetes API, konfigurasikan dengan flag --etcd-certfile=k8sclient.cert,--etcd-keyfile=k8sclient.key dan --etcd-cafile=ca.cert.
Catatan: Otentikasi etcd saat ini tidak didukung oleh Kubernetes. Untuk informasi lebih lanjut, lihat masalah terkait Mendukung Auth Dasar untuk Etcd v2.
Mengganti anggota etcd yang gagal
Etcd klaster mencapai ketersediaan tinggi dengan mentolerir kegagalan dari sebagian kecil anggota. Namun, untuk meningkatkan kesehatan keseluruhan dari klaster, segera ganti anggota yang gagal. Ketika banyak anggota yang gagal, gantilah satu per satu. Mengganti anggota yang gagal melibatkan dua langkah: menghapus anggota yang gagal dan menambahkan anggota baru.
Meskipun etcd menyimpan ID anggota unik secara internal, disarankan untuk menggunakan nama unik untuk setiap anggota untuk menghindari kesalahan manusia. Sebagai contoh, sebuah klaster etcd dengan tiga anggota. Jadikan URL-nya, member1=http://10.0.0.1, member2=http://10.0.0.2, and member3=http://10.0.0.3. Ketika member1 gagal, ganti dengan member4=http://10.0.0.4.
-
Dapatkan ID anggota yang gagal dari member1:
etcdctl --endpoints=http://10.0.0.2,http://10.0.0.3 member listAkan tampil pesan berikut:
8211f1d0f64f3269, started, member1, http://10.0.0.1:2380, http://10.0.0.1:2379 91bc3c398fb3c146, started, member2, http://10.0.0.2:2380, http://10.0.0.2:2379 fd422379fda50e48, started, member3, http://10.0.0.3:2380, http://10.0.0.3:2379 -
Hapus anggota yang gagal:
etcdctl member remove 8211f1d0f64f3269Akan tampil pesan berikut:
Removed member 8211f1d0f64f3269 from cluster -
Tambahkan anggota baru:
./etcdctl member add member4 --peer-urls=http://10.0.0.4:2380Akan tampil pesan berikut:
Member 2be1eb8f84b7f63e added to cluster ef37ad9dc622a7c4 -
Jalankan anggota yang baru ditambahkan pada mesin dengan IP
10.0.0.4:export ETCD_NAME="member4" export ETCD_INITIAL_CLUSTER="member2=http://10.0.0.2:2380,member3=http://10.0.0.3:2380,member4=http://10.0.0.4:2380" export ETCD_INITIAL_CLUSTER_STATE=existing etcd [flags] -
Lakukan salah satu dari yang berikut:
- Perbarui flag
--etcd-serveruntuk membuat Kubernetes mengetahui perubahan konfigurasi, lalu start ulang server API Kubernetes. - Perbarui konfigurasi load balancer jika load balancer digunakan dalam Deployment.
- Perbarui flag
Untuk informasi lebih lanjut tentang konfigurasi ulang klaster, lihat Dokumentasi Konfigurasi etcd.
Mencadangkan klaster etcd
Semua objek Kubernetes disimpan dalam etcd. Mencadangkan secara berkala data klaster etcd penting untuk memulihkan klaster Kubernetes di bawah skenario bencana, seperti kehilangan semua Node control plane. Berkas snapshot berisi semua status Kubernetes dan informasi penting. Untuk menjaga data Kubernetes yang sensitif aman, enkripsi berkas snapshot.
Mencadangkan klaster etcd dapat dilakukan dengan dua cara: snapshot etcd bawaan dan snapshot volume.
Snapshot bawaan
Fitur snapshot didukung oleh etcd secara bawaan, jadi mencadangkan klaster etcd lebih mudah. Snapshot dapat diambil dari anggota langsung dengan command etcdctl snapshot save atau dengan menyalin member/snap/db berkas dari etcd direktori data yang saat ini tidak digunakan oleh proses etcd. Mengambil snapshot biasanya tidak akan mempengaruhi kinerja anggota.
Di bawah ini adalah contoh untuk mengambil snapshot dari keyspace yang dilayani oleh $ENDPOINT ke berkas snapshotdb:
ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshotdb
# keluar 0
# memverifikasi hasil snapshot
ETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshotdb
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| fe01cf57 | 10 | 7 | 2.1 MB |
+----------+----------+------------+------------+
Snapshot volume
Jika etcd berjalan pada volume penyimpanan yang mendukung cadangan, seperti Amazon Elastic Block Store, buat cadangan data etcd dengan mengambil snapshot dari volume penyimpanan.
Memperbesar skala dari klaster etcd
Peningkatan skala klaster etcd meningkatkan ketersediaan dengan menukarnya untuk kinerja. Penyekalaan tidak akan meningkatkan kinerja atau kemampuan klaster. Aturan umum adalah untuk tidak melakukan penyekalaan naik atau turun untuk klaster etcd. Jangan mengonfigurasi grup penyekalaan otomatis untuk klaster etcd. Sangat disarankan untuk selalu menjalankan klaster etcd statis dengan lima anggota untuk klaster produksi Kubernetes untuk setiap skala yang didukung secara resmi.
Penyekalaan yang wajar adalah untuk meningkatkan klaster dengan tiga anggota menjadi dengan lima anggota, ketika dibutuhkan lebih banyak keandalan. Lihat Dokumentasi Rekonfigurasi etcd untuk informasi tentang cara menambahkan anggota ke klaster yang ada.
Memulihkan klaster etcd
Etcd mendukung pemulihan dari snapshot yang diambil dari proses etcd dari versi major.minor. Memulihkan versi dari versi patch lain dari etcd juga didukung. Operasi pemulihan digunakan untuk memulihkan data klaster yang gagal.
Sebelum memulai operasi pemulihan, berkas snapshot harus ada. Ini bisa berupa berkas snapshot dari operasi pencadangan sebelumnya, atau dari sisa direktori data. Untuk informasi dan contoh lebih lanjut tentang memulihkan klaster dari berkas snapshot, lihat dokumentasi pemulihan bencana etcd.
Jika akses URL dari klaster yang dipulihkan berubah dari klaster sebelumnya, maka server API Kubernetes harus dikonfigurasi ulang sesuai dengan URL tersebut. Pada kasus ini, start kembali server API Kubernetes dengan flag --etcd-servers=$NEW_ETCD_CLUSTER bukan flag --etcd-servers=$OLD_ETCD_CLUSTER. Ganti $NEW_ETCD_CLUSTER dan $OLD_ETCD_CLUSTER dengan alamat IP masing-masing. Jika load balancer digunakan di depan klaster etcd, kamu mungkin hanya perlu memperbarui load balancer sebagai gantinya.
Jika mayoritas anggota etcd telah gagal secara permanen, klaster etcd dianggap gagal. Dalam skenario ini, Kubernetes tidak dapat membuat perubahan apa pun ke kondisi saat ini. Meskipun Pod terjadwal mungkin terus berjalan, tidak ada Pod baru yang bisa dijadwalkan. Dalam kasus seperti itu, pulihkan klaster etcd dan kemungkinan juga untuk mengonfigurasi ulang server API Kubernetes untuk memperbaiki masalah ini.
Memutakhirkan dan memutar balikan klaster etcd
Pada Kubernetes v1.13.0, etcd2 tidak lagi didukung sebagai backend penyimpanan untuk klaster Kubernetes baru atau yang sudah ada. Timeline untuk dukungan Kubernetes untuk etcd2 dan etcd3 adalah sebagai berikut:
- Kubernetes v1.0: hanya etcd2
- Kubernetes v1.5.1: dukungan etcd3 ditambahkan, standar klaster baru yang dibuat masih ke etcd2
- Kubernetes v1.6.0: standar klaster baru yang dibuat dengan
kube-up.shadalah etcd3, dankube-apiserverstandarnya ke etcd3 - Kubernetes v1.9.0: pengumuman penghentian backend penyimpanan etcd2 diumumkan
- Kubernetes v1.13.0: backend penyimpanan etcd2 dihapus,
kube-apiserverakan menolak untuk start dengan--storage-backend=etcd2, dengan pesanetcd2 is no longer a supported storage backend
Sebelum memutakhirkan v1.12.x kube-apiserver menggunakan --storage-backend=etcd2 ke
v1.13.x, data etcd v2 harus dimigrasikan ke backend penyimpanan v3 dan
permintaan kube-apiserver harus diubah untuk menggunakan --storage-backend=etcd3.
Proses untuk bermigrasi dari etcd2 ke etcd3 sangat tergantung pada bagaimana klaster etcd diluncurkan dan dikonfigurasi, serta bagaimana klaster Kubernetes diluncurkan dan dikonfigurasi. Kami menyarankan kamu berkonsultasi dengan dokumentasi penyedia kluster kamu untuk melihat apakah ada solusi yang telah ditentukan.
Jika klaster kamu dibuat melalui kube-up.sh dan masih menggunakan etcd2 sebagai penyimpanan backend, silakan baca Kubernetes v1.12 etcd cluster upgrade docs
Masalah umum: penyeimbang klien etcd dengan secure endpoint
Klien etcd v3, dirilis pada etcd v3.3.13 atau sebelumnya, memiliki critical bug yang mempengaruhi kube-apiserver dan penyebaran HA. Pemindahan kegagalan (failover) penyeimbang klien etcd tidak bekerja dengan baik dengan secure endpoint. Sebagai hasilnya, server etcd boleh gagal atau terputus sesaat dari kube-apiserver. Hal ini mempengaruhi peluncuran HA dari kube-apiserver.
Perbaikan dibuat di etcd v3.4 (dan di-backport ke v3.3.14 atau yang lebih baru): klien baru sekarang membuat bundel kredensial sendiri untuk menetapkan target otoritas dengan benar dalam fungsi dial.
Karena perbaikan tersebut memerlukan pemutakhiran dependensi dari gRPC (ke v1.23.0), downstream Kubernetes tidak mendukung upgrade etcd, yang berarti perbaikan etcd di kube-apiserver hanya tersedia mulai Kubernetes 1.16.
Untuk segera memperbaiki celah keamanan (bug) ini untuk Kubernetes 1.15 atau sebelumnya, buat kube-apiserver khusus. kamu dapat membuat perubahan lokal ke vendor/google.golang.org/grpc/credentials/credentials.go dengan etcd@db61ee106.
Lihat "kube-apiserver 1.13.x menolak untuk bekerja ketika server etcd pertama tidak tersedia".