This the multi-page printable view of this section. Click here to print.
Documentazione
- 1: Glossary
- 2: Documentazione di Kubernetes
- 3: Concetti
- 3.1: Overview
- 3.1.1: Cos'è Kubernetes?
- 3.1.2: I componenti di Kubernetes
- 3.1.3: Le API di Kubernetes
- 3.2: Architettura di Kubernetes
- 3.2.1: Comunicazione Control Plane - Nodo
- 3.2.2: Concetti alla base del Cloud Controller Manager
- 3.2.3: Controller
- 3.3: Containers
- 3.3.1: Immagini
- 3.3.2: Container Environment
- 3.3.3: Container Lifecycle Hooks
- 3.4: Amministrazione del Cluster
- 3.4.1: Proxy in Kubernetes
- 3.5: Esempio di modello di concetto
- 4: Tutorials
- 4.1: Hello Minikube
1 - Glossary
2 - Documentazione di Kubernetes
3 - Concetti
La sezione Concetti ti aiuta a conoscere le parti del sistema Kubernetes e le astrazioni utilizzate da Kubernetes per rappresentare il tuo cluster e ti aiuta ad ottenere una comprensione più profonda di come funziona Kubernetes.
Overview
Per lavorare con Kubernetes, usi gli oggetti API Kubernetes per descrivere lo stato desiderato del tuo cluster: quali applicazioni o altri carichi di lavoro vuoi eseguire, quali immagini del contenitore usano, numero di repliche, quali risorse di rete e disco vuoi rendere disponibile e altro ancora. Puoi impostare lo stato desiderato creando oggetti usando l'API di Kubernetes, in genere tramite l'interfaccia della riga di comando, kubectl. Puoi anche utilizzare direttamente l'API di Kubernetes per interagire con il cluster e impostare o modificare lo stato desiderato.
Una volta impostato lo stato desiderato, il Kubernetes Control Plane funziona per fare in modo che lo stato corrente del cluster corrisponda allo stato desiderato. Per fare ciò, Kubernetes esegue automaticamente una serie di attività, come l'avvio o il riavvio dei contenitori, il ridimensionamento del numero di repliche di una determinata applicazione e altro ancora. Il piano di controllo di Kubernetes è costituito da una raccolta di processi in esecuzione sul cluster:
- Il Kubernetes Master è una raccolta di tre processi che vengono eseguiti su un singolo nodo nel cluster, che è designato come nodo principale. Questi processi sono: kube-apiserver, kube-controller-manager e kube-scheduler.
- Ogni singolo nodo non principale nel cluster esegue due processi: * kubelet, che comunica con il master di Kubernetes. * kube-proxy, un proxy di rete che riflette i servizi di rete di Kubernetes su ciascun nodo.
Kubernetes Objects
kubernetes contiene una serie di astrazioni che rappresentano lo stato del tuo sistema: applicazioni e carichi di lavoro distribuiti in container, le loro risorse di rete e disco associate e altre informazioni su ciò che sta facendo il tuo cluster. Queste astrazioni sono rappresentate da oggetti nell'API di Kubernetes; guarda la Panoramica degli oggetti di Kubernetes per maggiori dettagli.
Gli oggetti di base di Kubernetes includono:
209/5000 Inoltre, Kubernetes contiene una serie di astrazioni di livello superiore denominate Controllori. I controller si basano sugli oggetti di base e forniscono funzionalità aggiuntive e funzionalità di convenienza. Loro includono:
Kubernetes Control Plane
Le varie parti del Piano di controllo di Kubernetes, come i master Kubernetes e i processi di Kubelet, regolano il modo in cui Kubernetes comunica con il cluster. Il Piano di controllo mantiene un registro di tutti gli oggetti Kubernetes nel sistema e esegue cicli di controllo continui per gestire lo stato di tali oggetti. In qualsiasi momento, i loop di controllo di Control Plane risponderanno ai cambiamenti nel cluster e lavoreranno per fare in modo che lo stato effettivo di tutti gli oggetti nel sistema corrisponda allo stato desiderato che hai fornito.
Ad esempio, quando si utilizza l'API di Kubernetes per creare un oggetto di distribuzione, si fornisce un nuovo stato desiderato per il sistema. Il piano di controllo di Kubernetes registra la creazione dell'oggetto e svolge le tue istruzioni avviando le applicazioni richieste e pianificandole sui nodi del cluster, in modo che lo stato effettivo del cluster corrisponda allo stato desiderato.
Kubernetes Master
Il master Kubernetes è responsabile della gestione dello stato desiderato per il tuo cluster. Quando interagisci con Kubernetes, ad esempio utilizzando l'interfaccia della riga di comando kubectl, stai comunicando con il master di Kubernetes del cluster.
Il "master" si riferisce a una raccolta di processi che gestiscono lo stato del cluster. In genere questi processi vengono eseguiti tutti su un singolo nodo nel cluster e questo nodo viene anche definito master. Il master può anche essere replicato per disponibilità e ridondanza.
Kubernetes Nodes
I nodi di un cluster sono le macchine (VM, server fisici, ecc.) che eseguono i flussi di lavoro delle applicazioni e del cloud. Il master Kubernetes controlla ciascun nodo; raramente interagirai direttamente con i nodi.
Object Metadata
Voci correlate
Se vuoi scrivere una pagina concettuale, vedi Uso dei modelli di pagina per informazioni sul tipo di pagina di concetto e il modello di concetto.
3.1 - Overview
3.1.1 - Cos'è Kubernetes?
Questa pagina è una panoramica generale su Kubernetes.
Kubernetes è una piattaforma portatile, estensibile e open-source per la gestione di carichi di lavoro e servizi containerizzati, in grado di facilitare sia la configurazione dichiarativa che l'automazione. La piattaforma vanta un grande ecosistema in rapida crescita. Servizi, supporto e strumenti sono ampiamente disponibili nel mondo Kubernetes .
Il nome Kubernetes deriva dal greco, significa timoniere o pilota. Google ha reso open-source il progetto Kubernetes nel 2014. Kubernetes unisce oltre quindici anni di esperienza di Google nella gestione di carichi di lavoro di produzione su scala mondiale con le migliori idee e pratiche della comunità.
Facciamo un piccolo salto indietro
Diamo un'occhiata alla ragione per cui Kubernetes è così utile facendo un piccolo salto indietro nel tempo.

L'era del deployment tradizionale: All'inizio, le organizzazioni eseguivano applicazioni su server fisici. Non c'era modo di definire i limiti delle risorse per le applicazioni in un server fisico e questo ha causato non pochi problemi di allocazione delle risorse. Ad esempio, se più applicazioni vengono eseguite sullo stesso server fisico, si possono verificare casi in cui un'applicazione assorbe la maggior parte delle risorse e, di conseguenza, le altre applicazioni non hanno le prestazioni attese. Una soluzione per questo sarebbe di eseguire ogni applicazione su un server fisico diverso. Ma questa non è una soluzione ideale, dal momento che le risorse vengono sottoutilizzate, inoltre, questa pratica risulta essere costosa per le organizzazioni, le quali devono mantenere numerosi server fisici.
L'era del deployment virtualizzato: Come soluzione venne introdotta la virtualizzazione. Essa consente di eseguire più macchine virtuali (VM) su una singola CPU fisica. La virtualizzazione consente di isolare le applicazioni in più macchine virtuali e fornisce un livello di sicurezza superiore, dal momento che le informazioni di un'applicazione non sono liberamente accessibili da un'altra applicazione.
La virtualizzazione consente un migliore utilizzo delle risorse riducendo i costi per l'hardware, permette una migliore scalabilità, dato che un'applicazione può essere aggiunta o aggiornata facilmente, e ha molti altri vantaggi.
Ogni VM è una macchina completa che esegue tutti i componenti, compreso il proprio sistema operativo, sopra all'hardware virtualizzato.
L'era del deployment in container: I container sono simili alle macchine virtuali, ma presentano un modello di isolamento più leggero, condividendo il sistema operativo (OS) tra le applicazioni. Pertanto, i container sono considerati più leggeri. Analogamente a una macchina virtuale, un container dispone di una segregazione di filesystem, CPU, memoria, PID e altro ancora. Poiché sono disaccoppiati dall'infrastruttura sottostante, risultano portabili tra differenti cloud e diverse distribuzioni.
I container sono diventati popolari dal momento che offrono molteplici vantaggi, ad esempio:
- Creazione e distribuzione di applicazioni in modalità Agile: maggiore facilità ed efficienza nella creazione di immagini container rispetto all'uso di immagini VM.
- Adozione di pratiche per lo sviluppo/test/rilascio continuativo: consente la frequente creazione e la distribuzione di container image affidabili, dando la possibilità di fare rollback rapidi e semplici (grazie all'immutabilità dell'immagine stessa).
- Separazione delle fasi di Dev e Ops: le container image vengono prodotte al momento della compilazione dell'applicativo piuttosto che nel momento del rilascio, permettendo così di disaccoppiare le applicazioni dall'infrastruttura sottostante.
- L'osservabilità non riguarda solo le informazioni e le metriche del sistema operativo, ma anche lo stato di salute e altri segnali dalle applicazioni.
- Coerenza di ambiente tra sviluppo, test e produzione: i container funzionano allo stesso modo su un computer portatile come nel cloud.
- Portabilità tra cloud e sistemi operativi differenti: lo stesso container funziona su Ubuntu, RHEL, CoreOS, on-premise, nei più grandi cloud pubblici e da qualsiasi altra parte.
- Gestione incentrata sulle applicazioni: Aumenta il livello di astrazione dall'esecuzione di un sistema operativo su hardware virtualizzato all'esecuzione di un'applicazione su un sistema operativo utilizzando risorse logiche.
- Microservizi liberamente combinabili, distribuiti, ad alta scalabilità: le applicazioni sono suddivise in pezzi più piccoli e indipendenti che possono essere distribuite e gestite dinamicamente - niente stack monolitici che girano su una singola grande macchina.
- Isolamento delle risorse: le prestazioni delle applicazioni sono prevedibili.
- Utilizzo delle risorse: alta efficienza e densità.
Perché necessito di Kubernetes e cosa posso farci
I container sono un buon modo per distribuire ed eseguire le tue applicazioni. In un ambiente di produzione, è necessario gestire i container che eseguono le applicazioni e garantire che non si verifichino interruzioni dei servizi. Per esempio, se un container si interrompe, è necessario avviare un nuovo container. Non sarebbe più facile se questo comportamento fosse gestito direttamente da un sistema?
È proprio qui che Kubernetes viene in soccorso! Kubernetes ti fornisce un framework per far funzionare i sistemi distribuiti in modo resiliente. Kubernetes si occupa della scalabilità, failover, distribuzione delle tue applicazioni. Per esempio, Kubernetes può facilmente gestire i rilasci con modalità Canary deployment.
Kubernetes ti fornisce:
- Scoperta dei servizi e bilanciamento del carico Kubernetes può esporre un container usando un nome DNS o il suo indirizzo IP. Se il traffico verso un container è alto, Kubernetes è in grado di distribuire il traffico su più container in modo che il servizio rimanga stabile.
- Orchestrazione dello storage Kubernetes ti permette di montare automaticamente un sistema di archiviazione di vostra scelta, come per esempio storage locale, dischi forniti da cloud pubblici, e altro ancora.
- Rollout e rollback automatizzati Puoi utilizzare Kubernetes per descrivere lo stato desiderato per i propri container, e Kubernetes si occuperà di cambiare lo stato attuale per raggiungere quello desiderato ad una velocità controllata. Per esempio, puoi automatizzare Kubernetes per creare nuovi container per il tuo servizio, rimuovere i container esistenti e adattare le loro risorse a quelle richieste dal nuovo container.
- Ottimizzazione dei carichi Fornisci a Kubernetes un cluster di nodi per eseguire i container. Puoi istruire Kubernetes su quanta CPU e memoria (RAM) ha bisogno ogni singolo container. Kubernetes allocherà i container sui nodi per massimizzare l'uso delle risorse a disposizione.
- Self-healing Kubernetes riavvia i container che si bloccano, sostituisce container, termina i container che non rispondono agli health checks, e evita di far arrivare traffico ai container che non sono ancora pronti per rispondere correttamente.
- Gestione di informazioni sensibili e della configurazione Kubernetes consente di memorizzare e gestire informazioni sensibili, come le password, i token OAuth e le chiavi SSH. Puoi distribuire e aggiornare le informazioni sensibili e la configurazione dell'applicazione senza dover ricostruire le immagini dei container e senza svelare le informazioni sensibili nella configurazione del tuo sistema.
Cosa non è Kubernetes
Kubernetes non è un sistema PaaS (Platform as a Service) tradizionale e completo. Dal momento che Kubernetes opera a livello di container piuttosto che che a livello hardware, esso fornisce alcune caratteristiche generalmente disponibili nelle offerte PaaS, come la distribuzione, il ridimensionamento, il bilanciamento del carico, la registrazione e il monitoraggio. Tuttavia, Kubernetes non è monolitico, e queste soluzioni predefinite sono opzionali ed estensibili. Kubernetes fornisce gli elementi base per la costruzione di piattaforme di sviluppo, ma conserva le scelte dell'utente e la flessibilità dove è importante.
Kubernetes:
- Non limita i tipi di applicazioni supportate. Kubernetes mira a supportare una grande varietà di carichi di lavoro, compresi i carichi di lavoro stateless, stateful e elaborazione di dati. Se un'applicazione può essere eseguita in un container, dovrebbe funzionare alla grande anche su Kubernetes.
- Non compila il codice sorgente e non crea i container. I flussi di Continuous Integration, Delivery, and Deployment (CI/CD) sono determinati dalla cultura e dalle preferenze dell'organizzazione e dai requisiti tecnici.
- Non fornisce servizi a livello applicativo, come middleware (per esempio, bus di messaggi), framework di elaborazione dati (per esempio, Spark), database (per esempio, mysql), cache, né sistemi di storage distribuito (per esempio, Ceph) come servizi integrati. Tali componenti possono essere eseguiti su Kubernetes, e/o possono essere richiamati da applicazioni che girano su Kubernetes attraverso meccanismi come l'Open Service Broker.
- Non impone soluzioni di logging, monitoraggio o di gestione degli alert. Fornisce alcune integrazioni come dimostrazione, e meccanismi per raccogliere ed esportare le metriche.
- Non fornisce né rende obbligatorio un linguaggio/sistema di configurazione (per esempio, Jsonnet). Fornisce un'API dichiarativa che può essere richiamata da qualsiasi sistema.
- Non fornisce né adotta alcun sistema di gestione completa della macchina, configurazione, manutenzione, gestione o sistemi di self healing.
- Inoltre, Kubernetes non è un semplice sistema di orchestrazione. Infatti, questo sistema elimina la necessità di orchestrazione. La definizione tecnica di orchestrazione è l'esecuzione di un flusso di lavoro definito: prima si fa A, poi B, poi C. Al contrario, Kubernetes è composto da un insieme di processi di controllo indipendenti e componibili che guidano costantemente lo stato attuale verso lo stato desiderato. Non dovrebbe importare come si passa dalla A alla C. Anche il controllo centralizzato non è richiesto. Questo si traduce in un sistema più facile da usare, più potente, robusto, resiliente ed estensibile.
Voci correlate
- Dai un'occhiata alla pagina i componenti di Kubernetes
- Sai già Come Iniziare?
3.1.2 - I componenti di Kubernetes
Facendo il deployment di Kubernetes, ottieni un cluster.
Un cluster Kubernetes è un'insieme di macchine, chiamate nodi, che eseguono container gestiti da Kubernetes. Un cluster ha almeno un Worker Node.
Il/I Worker Node ospitano i Pod che eseguono i workload dell'utente. Il/I Control Plane Node gestiscono i Worker Node e tutto quanto accade all'interno del cluster. Per garantire la high-availability e la possibilità di failover del cluster, vengono utilizzati più Control Plane Node.
Questo documento descrive i diversi componenti che sono necessari per avere un cluster Kubernetes completo e funzionante.
Questo è un diagramma di un cluster Kubernetes con tutti i componenti e le loro relazioni.
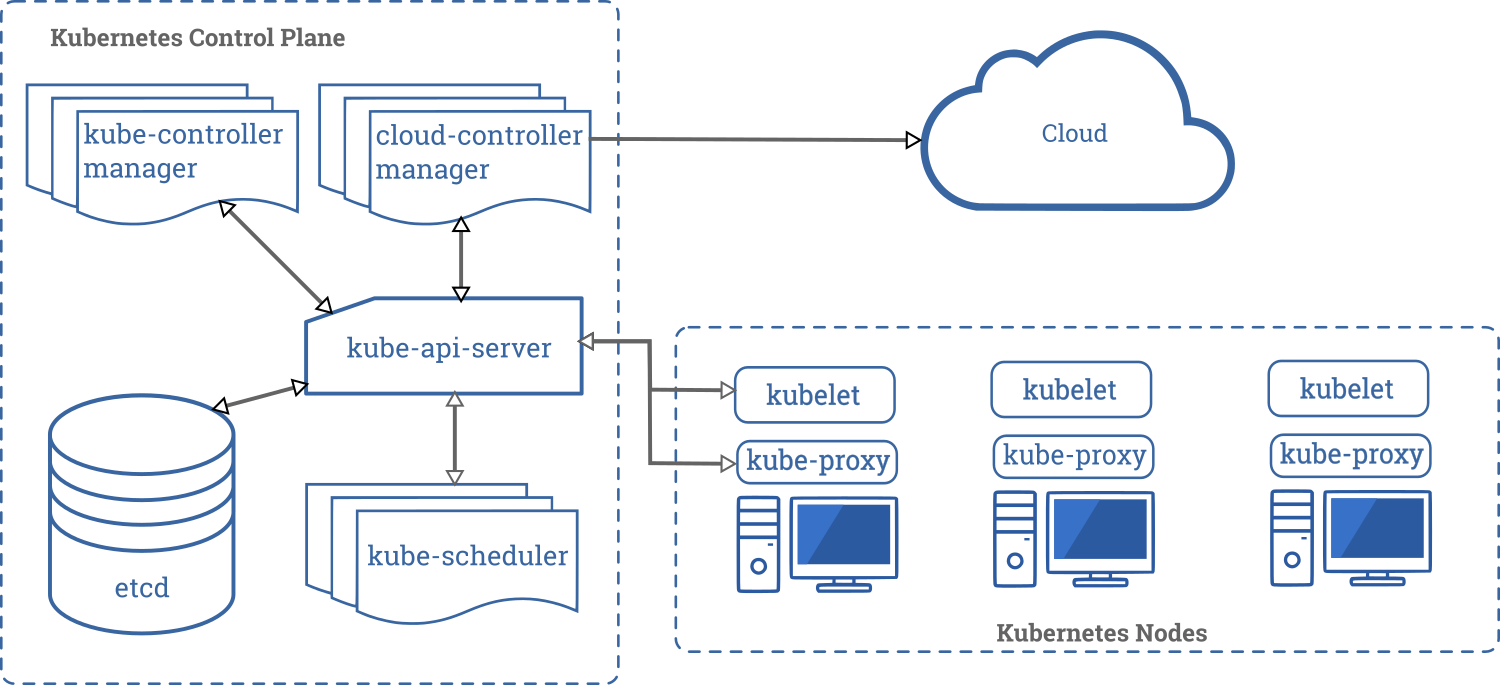
Componenti della Control Plane
I componenti del Control Plane sono responsabili di tutte le decisioni globali sul cluster (ad esempio, lo scheduling) oltre che a rilevare e rispondere agli eventi del cluster (ad esempio, l'avvio di un nuovo pod quando il valore replicas di un deployment non è soddisfatto).
I componenti della Control Plane possono essere eseguiti su qualsiasi nodo del cluster stesso. Solitamente, per semplicità, gli script di installazione tendono a eseguire tutti i componenti della Control Plane sulla stessa macchina, separando la Control Plane dai workload dell'utente. Vedi creare un cluster in High-Availability per un esempio di un'installazione multi-master.
kube-apiserver
L'API server è un componente di Kubernetes control plane che espone le Kubernetes API. L'API server è il front end del control plane di Kubernetes.
La principale implementazione di un server Kubernetes API è kube-apiserver. kube-apiserver è progettato per scalare orizzontalmente, cioè scala aumentando il numero di istanze. Puoi eseguire multiple istanze di kube-apiserver e bilanciare il traffico tra queste istanze.
etcd
È un database key-value ridondato, che è usato da Kubernetes per salvare tutte le informazioni del cluster.
Se il tuo cluster utilizza etcd per salvare le informazioni, assicurati di avere una strategia di backup per questi dati.
Puoi trovare informazioni dettagliate su etcd sulla documentazione ufficiale.
kube-scheduler
Componente della Control Plane che controlla i pod appena creati che non hanno un nodo assegnato, e dopo averlo identificato glielo assegna.
I fattori presi in considerazioni nell'individuare un nodo a cui assegnare l'esecuzione di un Pod includono la richiesta di risorse del Pod stesso e degli altri workload presenti nel sistema, i vincoli delle hardware/software/policy, le indicazioni di affinity e di anti-affinity, requisiti relativi alla disponibilità di dati/Volumes, le interferenze tra diversi workload e le scadenze.
kube-controller-manager
Componente della Control Plane che gestisce controllers.
Da un punto di vista logico, ogni controller è un processo separato, ma per ridurre la complessità, tutti i principali controller di Kubernetes vengono raggruppati in un unico container ed eseguiti in un singolo processo.
Alcuni esempi di controller gestiti dal kube-controller-manager sono:
- Node Controller: Responsabile del monitoraggio dei nodi del cluster, e.g. della gestione delle azioni da eseguire quando un nodo diventa non disponibile.
- Replication Controller: Responsabile per il mantenimento del corretto numero di Pod per ogni ReplicaSet presente nel sistema
- Endpoints Controller: Popola gli oggetti Endpoints (cioè, mette in relazioni i Pods con i Services).
- Service Account & Token Controllers: Creano gli account di default e i token di accesso alle API per i nuovi namespaces.
cloud-controller-manager
Un componente della control plane di Kubernetes che aggiunge logiche di controllo specifiche per il cloud. Il cloud-controller-manager ti permette di collegare il tuo cluster con le API del cloud provider e separa le componenti che interagiscono con la piattaforma cloud dai componenti che interagiscono solamente col cluster.Il cloud-controller-manager esegue dei controller specifici del tuo cloud provider. Se hai una installazione Kubernetes on premises, o un ambiente di laboratorio nel tuo PC, il cluster non ha un cloud-controller-manager.
Come nel kube-controller-manager, il cloud-controller-manager combina diversi control loop logicamente indipendenti in un singolo binario che puoi eseguire come un singolo processo. Tu puoi scalare orizzontalmente (eseguire più di una copia) per migliorare la responsività o per migliorare la tolleranza ai fallimenti.
I seguenti controller hanno dipendenze verso implementazioni di specifici cloud provider:
- Node Controller: Per controllare se sul cloud provider i nodi che hanno smesso di rispondere sono stati cancellati
- Route Controller: Per configurare le network route nella sottostante infrastruttura cloud
- Service Controller: Per creare, aggiornare ed eliminare i load balancer del cloud provider
Componenti dei Nodi
I componenti del nodo vengono eseguiti su ogni nodo, mantenendo i pod in esecuzione e fornendo l'ambiente di runtime Kubernetes.
kubelet
Un agente che è eseguito su ogni nodo del cluster. Si assicura che i container siano eseguiti in un pod.
La kubelet riceve un set di PodSpecs che vengono forniti attraverso vari meccanismi, e si assicura che i container descritti in questi PodSpecs funzionino correttamente e siano sani. La kubelet non gestisce i container che non sono stati creati da Kubernetes.
kube-proxy
kube-proxy è un proxy eseguito su ogni nodo del cluster, responsabile della gestione dei Kubernetes Service.
I kube-proxy mantengono le regole di networking sui nodi. Queste regole permettono la comunicazione verso gli altri nodi del cluster o l'esterno.
Il kube-proxy usa le librerie del sistema operativo quando possible; in caso contrario il kube-proxy gestisce il traffico direttamente.
Container Runtime
Il container runtime è il software che è responsabile per l'esecuzione dei container.
Kubernetes supporta diversi container runtimes: Docker, containerd, cri-o, rktlet e tutte le implementazioni di Kubernetes CRI (Container Runtime Interface).
Addons
Gli Addons usano le risorse Kubernetes (DaemonSet, Deployment, etc) per implementare funzionalità di cluster.
Dal momento che gli addons forniscono funzionalità a livello di cluster, le risorse che necessitano di un namespace, vengono collocate nel namespace kube-system.
Alcuni addons sono descritti di seguito; mentre per una più estesa lista di addons, per favore vedere Addons.
DNS
Mentre gli altri addons non sono strettamente richiesti, tutti i cluster Kubernetes dovrebbero essere muniti di un DNS del cluster, dal momento che molte applicazioni lo necessitano.
Il DNS del cluster è un server DNS aggiuntivo rispetto ad altri server DNS presenti nella rete, e si occupa specificatamente dei record DNS per i servizi Kubernetes.
I container eseguiti da Kubernetes automaticamente usano questo server per la risoluzione DNS.
Interfaccia web (Dashboard)
La Dashboard è una interfaccia web per i cluster Kubernetes. Permette agli utenti di gestire e fare troubleshooting delle applicazioni che girano nel cluster, e del cluster stesso.
Monitoraggio dei Container
Il Monitoraggio dei Container salva serie temporali di metriche generiche dei container in un database centrale e fornisce una interfaccia in cui navigare i dati stessi.
Log a livello di Cluster
Un log a livello di cluster è responsabile per il salvataggio dei log dei container in un log centralizzato la cui interfaccia permette di cercare e navigare nei log.
Voci correlate
- Scopri i concetti relativi ai Nodi
- Scopri i concetti relativi ai Controller
- Scopri i concetti relativi al kube-scheduler
- Leggi la documentazione ufficiale di etcd
3.1.3 - Le API di Kubernetes
Le convenzioni generali seguite dalle API sono descritte in API conventions doc.
Gli endpoints delle API, la lista delle risorse esposte ed i relativi esempi sono descritti in API Reference.
L'accesso alle API da remoto è discusso in Controllare l'accesso alle API.
Le API di Kubernetes servono anche come riferimento per lo schema dichiarativo della configurazione del sistema stesso. Il comando kubectl può essere usato per creare, aggiornare, cancellare ed ottenere le istanze delle risorse esposte attraverso le API.
Kubernetes assicura la persistenza del suo stato (al momento in etcd) usando la rappresentazione delle risorse implementata dalle API.
Kubernetes stesso è diviso in differenti componenti, i quali interagiscono tra loro attraverso le stesse API.
Evoluzione delle API
In base alla nostra esperienza, ogni sistema di successo ha bisogno di evolvere ovvero deve estendersi aggiungendo funzionalità o modificare le esistenti per adattarle a nuovi casi d'uso. Le API di Kubernetes sono quindi destinate a cambiare e ad estendersi. In generale, ci si deve aspettare che nuove risorse vengano aggiunte di frequente cosi come nuovi campi possano altresì essere aggiunti a risorse esistenti. L'eliminazione di risorse o di campi devono seguire la politica di deprecazione delle API.
In cosa consiste una modifica compatibile e come modificare le API è descritto dal API change document.
Definizioni OpenAPI e Swagger
La documentazione completa e dettagliata delle API è fornita attraverso la specifica OpenAPI.
Dalla versione 1.10 di Kubernetes, l'API server di Kubernetes espone le specifiche OpenAPI attraverso il seguente endpoint /openapi/v2. Attraverso i seguenti headers HTTP è possibile richiedere un formato specifico:
| Header | Possibili Valori |
|---|---|
| Accept | application/json, application/com.github.proto-openapi.spec.v2@v1.0+protobuf (il content-type di default è application/json per */* ovvero questo header può anche essere omesso) |
| Accept-Encoding | gzip (questo header è facoltativo) |
Prima della versione 1.14, gli endpoints che includono il formato del nome all'interno del segmento (/swagger.json, /swagger-2.0.0.json, /swagger-2.0.0.pb-v1, /swagger-2.0.0.pb-v1.gz)
espongo le specifiche OpenAPI in formati differenti. Questi endpoints sono deprecati, e saranno rimossi dalla versione 1.14 di Kubernetes.
Esempi per ottenere le specifiche OpenAPI:
| Prima della 1.10 | Dalla versione 1.10 di Kubernetes |
|---|---|
| GET /swagger.json | GET /openapi/v2 Accept: application/json |
| GET /swagger-2.0.0.pb-v1 | GET /openapi/v2 Accept: application/com.github.proto-openapi.spec.v2@v1.0+protobuf |
| GET /swagger-2.0.0.pb-v1.gz | GET /openapi/v2 Accept: application/com.github.proto-openapi.spec.v2@v1.0+protobuf Accept-Encoding: gzip |
Kubernetes implementa per le sue API anche una serializzazione alternativa basata sul formato Protobuf che è stato pensato principalmente per la comunicazione intra-cluster, documentato nella seguente design proposal, e i files IDL per ciascun schema si trovano nei Go packages che definisco i tipi delle API.
Prima della versione 1.14, l'apiserver di Kubernetes espone anche un'endpoint, /swaggerapi, che può essere usato per ottenere
le documentazione per le API di Kubernetes secondo le specifiche Swagger v1.2 .
Questo endpoint è deprecato, ed è stato rimosso nella versione 1.14 di Kubernetes.
Versionamento delle API
Per facilitare l'eliminazione di campi specifici o la modifica della rappresentazione di una data risorsa, Kubernetes supporta molteplici versioni della stessa API disponibili attraverso differenti indirizzi, come ad esempio /api/v1 oppure
/apis/extensions/v1beta1.
Abbiamo deciso di versionare a livello di API piuttosto che a livello di risorsa o di campo per assicurare che una data API rappresenti una chiara, consistente vista delle risorse di sistema e dei sui comportamenti, e per abilitare un controllo degli accessi sia per le API in via di decommissionamento che per quelle sperimentali.
Si noti che il versionamento delle API ed il versionamento del Software sono indirettamente collegati. La API and release versioning proposal descrive la relazione tra le versioni delle API ed le versioni del Software.
Differenti versioni delle API implicano differenti livelli di stabilità e supporto. I criteri per ciascuno livello sono descritti in dettaglio nella API Changes documentation. Queste modifiche sono qui ricapitolate:
- Livello alpha:
- Il nome di versione contiene
alpha(e.g.v1alpha1). - Potrebbe contenere dei bug. Abilitare questa funzionalità potrebbe esporre al rischio di bugs. Disabilitata di default.
- Il supporto di questa funzionalità potrebbe essere rimosso in ogni momento senza previa notifica.
- Questa API potrebbe cambiare in modo incompatibile in rilasci futuri del Software e senza previa notifica.
- Se ne raccomandata l'utilizzo solo in clusters di test creati per un breve periodo di vita, a causa di potenziali bugs e delle mancanza di un supporto di lungo periodo.
- Il nome di versione contiene
- Livello beta:
- Il nome di versione contiene
beta(e.g.v2beta3). - Il codice è propriamente testato. Abilitare la funzionalità è considerato sicuro. Abilitata di default.
- Il supporto per la funzionalità nel suo complesso non sarà rimosso, tuttavia potrebbe subire delle modifiche.
- Lo schema e/o la semantica delle risorse potrebbe cambiare in modo incompatibile in successivi rilasci beta o stabili. Nel caso questo dovesse verificarsi, verrano fornite istruzioni per la migrazione alla versione successiva. Questo potrebbe richiedere la cancellazione, modifica, e la ri-creazione degli oggetti supportati da questa API. Questo processo di modifica potrebbe richiedere delle valutazioni. La modifica potrebbe richiedere un periodo di non disponibilità dell'applicazione che utilizza questa funzionalità.
- Raccomandata solo per applicazioni non critiche per la vostra impresa a causa dei potenziali cambiamenti incompatibili in rilasci successivi. Se avete più clusters che possono essere aggiornati separatamente, potreste essere in grado di gestire meglio questa limitazione.
- Per favore utilizzate le nostre versioni beta e forniteci riscontri relativamente ad esse! Una volta promosse a stabili, potrebbe non essere semplice apportare cambiamenti successivi.
- Il nome di versione contiene
- Livello stabile:
- Il nome di versione è
vXdoveXè un intero. - Le funzionalità relative alle versioni stabili continueranno ad essere presenti per parecchie versioni successive.
- Il nome di versione è
API groups
Per facilitare l'estendibilità delle API di Kubernetes, sono stati implementati gli API groups.
L'API group è specificato nel percorso REST ed anche nel campo apiVersion di un oggetto serializzato.
Al momento ci sono diversi API groups in uso:
-
Il gruppo core, spesso referenziato come il legacy group, è disponibile al percorso REST
/api/v1ed utilizzaapiVersion: v1. -
I gruppi basati su un nome specifico sono disponibili attraverso il percorso REST
/apis/$GROUP_NAME/$VERSION, ed usanoapiVersion: $GROUP_NAME/$VERSION(e.g.apiVersion: batch/v1). La lista completa degli API groups supportati e' descritta nel documento Kubernetes API reference.
Vi sono due modi per supportati per estendere le API attraverso le custom resources:
- CustomResourceDefinition è pensato per utenti con esigenze CRUD basilari.
- Utenti che necessitano di un nuovo completo set di API che utilizzi appieno la semantica di Kubernetes possono implementare il loro apiserver ed utilizzare l'aggregator per fornire ai propri utilizzatori la stessa esperienza a cui sono abituati con le API incluse nativamente in Kubernetes.
Abilitare o disabilitare gli API groups
Alcune risorse ed API groups sono abilitati di default. Questi posso essere abilitati o disabilitati attraverso il settaggio/flag --runtime-config
applicato sull'apiserver. --runtime-config accetta valori separati da virgola. Per esempio: per disabilitare batch/v1, usa la seguente configurazione --runtime-config=batch/v1=false, per abilitare batch/v2alpha1, utilizzate --runtime-config=batch/v2alpha1.
Il flag accetta set di coppie chiave/valore separati da virgola che descrivono la configurazione a runtime dell'apiserver.
Nota: Abilitare o disabilitare risorse o gruppi richiede il riavvio dell'apiserver e del controller-manager affinché le modifiche specificate attraverso il flag--runtime-configabbiano effetto.
Abilitare specifiche risorse nel gruppo extensions/v1beta1
DaemonSets, Deployments, StatefulSet, NetworkPolicies, PodSecurityPolicies e ReplicaSets presenti nel gruppo di API extensions/v1beta1 sono disabilitate di default.
Per esempio: per abilitare deployments and daemonsets, utilizza la seguente configurazione
--runtime-config=extensions/v1beta1/deployments=true,extensions/v1beta1/daemonsets=true.
Nota: Abilitare/disabilitare una singola risorsa è supportato solo per il gruppo di APIextensions/v1beta1per ragioni storiche.
3.2 - Architettura di Kubernetes
3.2.1 - Comunicazione Control Plane - Nodo
Questo documento cataloga le connessioni tra il piano di controllo (control-plane), in realtà l'apiserver, e il cluster Kubernetes. L'intento è di consentire agli utenti di personalizzare la loro installazione per rafforzare la configurazione di rete affinché il cluster possa essere eseguito su una rete pubblica (o su IP completamente pubblici resi disponibili da un fornitore di servizi cloud).
Dal Nodo al control-plane
Kubernetes adotta un pattern per le API di tipo "hub-and-spoke". Tutte le chiamate delle API eseguite sui vari nodi sono effettuate verso l'apiserver (nessuno degli altri componenti principali è progettato per esporre servizi remoti). L'apiserver è configurato per l'ascolto di connessioni remote su una porta HTTPS protetta (443) con una o più forme di autenticazioni client abilitate. Si dovrebbero abilitare una o più forme di autorizzazioni, in particolare nel caso in cui siano ammesse richieste anonime o token legati ad un account di servizio (service account).
Il certificato pubblico (public root certificate) relativo al cluster corrente deve essere fornito ai vari nodi di modo che questi possano connettersi in modo sicuro all'apiserver insieme alle credenziali valide per uno specifico client. Ad esempio, nella configurazione predefinita di un cluster GKE, le credenziali del client fornite al kubelet hanno la forma di un certificato client. Si veda inizializzazione TLS del kubelet TLS per la fornitura automatica dei certificati client al kubelet.
I Pod che desiderano connettersi all'apiserver possono farlo in modo sicuro sfruttando un account di servizio in modo che Kubernetes inserisca automaticamente il certificato pubblico di radice e un token valido al portatore (bearer token) all'interno Pod quando questo viene istanziato.
In tutti i namespace è configurato un Service con nome kubernetes con un indirizzo IP virtuale che viene reindirizzato (tramite kube-proxy) all'endpoint HTTPS dell'apiserver.
Anche i componenti del piano d controllo comunicano con l'apiserver del cluster su di una porta sicura esposta da quest'ultimo.
Di conseguenza, la modalità operativa predefinita per le connessioni dai nodi e dai Pod in esecuzione sui nodi verso il control-plane è protetta da un'impostazione predefinita e può essere eseguita su reti non sicure e/o pubbliche.
Dal control-plane al nodo
Esistono due percorsi di comunicazione principali dal control-plane (apiserver) verso i nodi. Il primo è dall'apiserver verso il processo kubelet in esecuzione su ogni nodo nel cluster. Il secondo è dall'apiserver a ciascun nodo, Pod, o servizio attraverso la funzionalità proxy dell'apiserver.
Dall'apiserver al kubelet
Le connessioni dall'apiserver al kubelet vengono utilizzate per:
- Prendere i log relativi ai vari Pod.
- Collegarsi (attraverso kubectl) ai Pod in esecuzione.
- Fornire la funzionalità di port-forwarding per i kubelet.
Queste connessioni terminano all'endpoint HTTPS del kubelet. Di default, l'apiserver non verifica il certificato servito dal kubelet, il che rende la connessione soggetta ad attacchi man-in-the-middle, e tale da essere considerato non sicuro (unsafe) se eseguito su reti non protette e/o pubbliche.
Per verificare questa connessione, si utilizzi il parametro --kubelet-certificate-authority al fine di fornire all'apiserver un insieme di certificati radice da utilizzare per verificare il
il certificato servito dal kubelet.
Se questo non è possibile, si usi un tunnel SSH tra l'apiserver e il kubelet, se richiesto, per evitare il collegamento su una rete non protetta o pubblica.
In fine, l'autenticazione e/o l'autorizzazione del kubelet dovrebbe essere abilitate per proteggere le API esposte dal kubelet.
Dall'apiserver ai nodi, Pod, e servizi
Le connessioni dall'apiserver verso un nodo, Pod o servizio avvengono in modalità predefinita su semplice connessione HTTP e quindi non sono né autenticate né criptata. Queste connessioni possono essere eseguite su una connessione HTTPS sicura mediante il prefisso https: al nodo, Pod o nome del servizio nell'URL dell'API, ma non valideranno il certificato fornito dall'endpoint HTTPS né forniranno le credenziali del client così anche se la connessione verrà criptata, non fornirà alcuna garanzia di integrità. Non è attualmente sicuro eseguire queste connessioni su reti non protette e/o pubbliche.
I tunnel SSH
Kubernetes supporta i tunnel SSH per proteggere la comunicazione tra il control-plane e i nodi. In questa configurazione, l'apiserver inizializza un tunnel SSH con ciascun nodo del cluster (collegandosi al server SSH in ascolto sulla porta 22) e fa passare tutto il traffico verso il kubelet, il nodo, il Pod, o il servizio attraverso questo tunnel. Questo tunnel assicura che il traffico non sia esposto al di fuori della rete su cui sono in esecuzioni i vari nodi.
I tunnel SSH sono al momento deprecati ovvero non dovrebbero essere utilizzati a meno che ci siano delle esigenze particolari. Il servizio Konnectivity è pensato per rimpiazzare questo canale di comunicazione.
Il servizio Konnectivity
Kubernetes v1.18 [beta]
Come rimpiazzo dei tunnel SSH, il servizio Konnectivity fornisce un proxy a livello TCP per la comunicazione tra il control-plane e il cluster. Il servizio Konnectivity consiste in due parti: il Konnectivity server e gli agenti Konnectivity, in esecuzione rispettivamente sul control-plane e sui vari nodi. Gli agenti Konnectivity inizializzano le connessioni verso il server Konnectivity e mantengono le connessioni di rete. Una volta abilitato il servizio Konnectivity, tutto il traffico tra il control-plane e i nodi passa attraverso queste connessioni.
Si può fare riferimento al tutorial per il servizio Konnectivity per configurare il servizio Konnectivity all'interno del cluster
3.2.2 - Concetti alla base del Cloud Controller Manager
Il concetto di CCM (cloud controller manager), da non confondere con il binario, è stato originariamente creato per consentire di sviluppare Kubernetes indipendentemente dall'implementazione dello specifico cloud provider. Il cloud controller manager viene eseguito insieme ad altri componenti principali come il Kubernetes controller manager, il server API e lo scheduler. Può anche essere avviato come addon di Kubernetes, nel qual caso viene eseguito su Kubernetes.
Il design del cloud controller manager è basato su un meccanismo di plug-in che consente ai nuovi provider cloud di integrarsi facilmente con Kubernetes creando un plug-in. Sono in atto programmi per l'aggiunta di nuovi provider di cloud su Kubernetes e per la migrazione dei provider che usano il vecchio metodo a questo nuovo metodo.
Questo documento discute i concetti alla base del cloud controller manager e fornisce dettagli sulle funzioni associate.
Ecco l'architettura di un cluster Kubernetes senza il gestore del controller cloud:
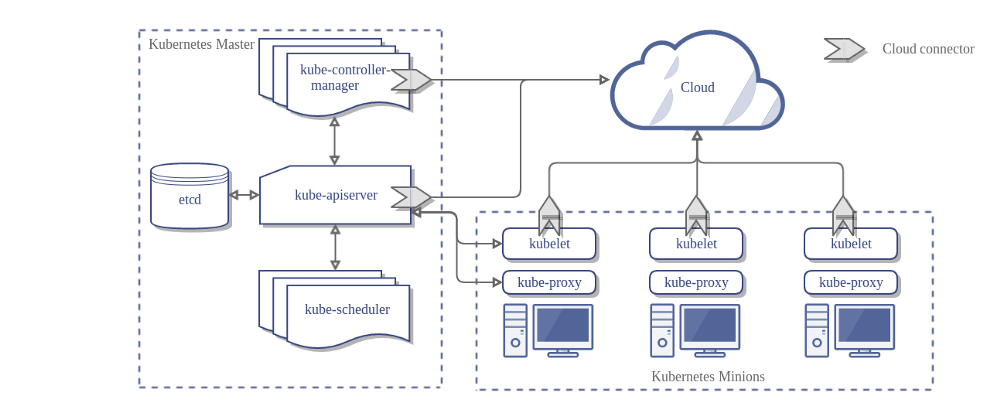
Architettura
Nel diagramma precedente, Kubernetes e il provider cloud sono integrati attraverso diversi componenti:
- Kubelet
- Kubernetes controller manager
- Kubernetes API server
Il CCM consolida tutta la logica dipendente dal cloud presente nei tre componenti precedenti, per creare un singolo punto di integrazione con il cloud. La nuova architettura con il CCM si presenta così:
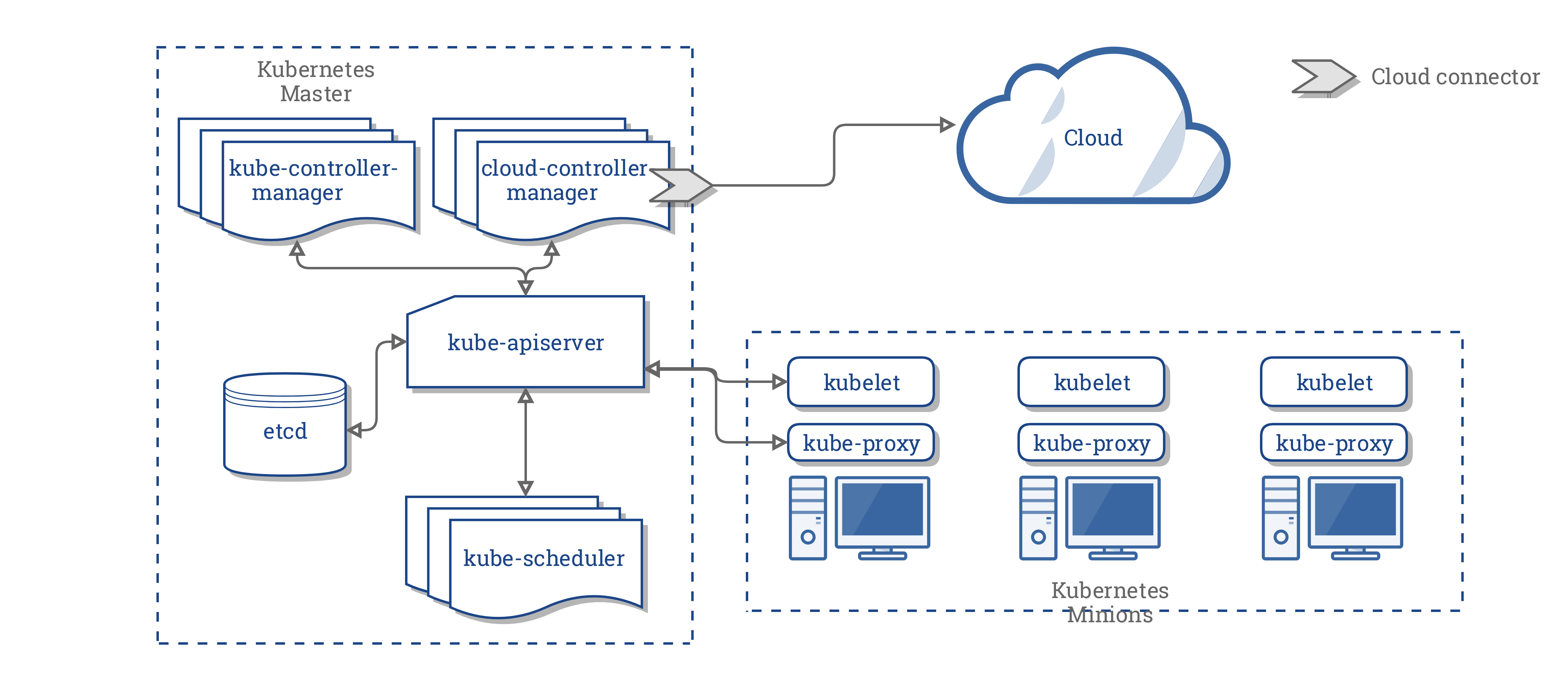
Componenti del CCM
Il CCM divide alcune funzionalità del Kubernetes controller manager (KCM) e le esegue in un differente processo. In particolare, toglie dal KCM le integrazioni con il cloud specifico. Il KCM ha i seguenti controller che dipendono dal cloud specifico:
- Node controller
- Volume controller
- Route controller
- Service controller
Nella versione 1.9, il CCM esegue i seguenti controller dall'elenco precedente:
- Node controller
- Route controller
- Service controller
Nota: È stato deliberatamente deciso di non spostare il Volume controller nel CCM. Data la complessità del Volume controller e gli sforzi già fatti per astrarre le logiche specifiche dei singoli fornitori, è stato deciso che il Volume controller non verrà spostato nel CCM.
Il piano originale per supportare i volumi utilizzando il CCM era di utilizzare Flex per supportare volumi collegabili. Tuttavia, una implementazione parallela, nota come CSI è stata designata per sostituire Flex.
Considerando queste evoluzioni, abbiamo deciso di adottare un approccio intermedio finché il CSI non è pronto.
Funzioni del CCM
Il CCM eredita le sue funzioni da componenti di Kubernetes che dipendono da uno specifico provider di cloud. Questa sezione è strutturata sulla base di tali componenti.
1. Kubernetes controller manager
La maggior parte delle funzioni del CCM deriva dal KCM. Come menzionato nella sezione precedente, CCM esegue i seguenti cicli di controllo:
- Node controller
- Route controller
- Service controller
Node controller
Il Node controller è responsabile per l'inizializzazione di un nodo ottenendo informazioni sui nodi in esecuzione nel cluster dal provider cloud. Il controller del nodo esegue le seguenti funzioni:
- Inizializzare un nodo con le label zone/region specifiche per il cloud in uso.
- Inizializzare un nodo con le specifiche, ad esempio, tipo e dimensione specifiche del cloud in uso.
- Ottenere gli indirizzi di rete del nodo e l'hostname.
- Nel caso in cui un nodo non risponda, controlla il cloud per vedere se il nodo è stato cancellato dal cloud. Se il nodo è stato eliminato dal cloud, elimina l'oggetto Nodo di Kubernetes.
Route controller
Il Route controller è responsabile della configurazione delle route nel cloud in modo che i container su nodi differenti del cluster Kubernetes possano comunicare tra loro. Il Route controller è utilizzabile solo dai cluster su Google Compute Engine.
Service Controller
Il Service Controller rimane in ascolto per eventi di creazione, aggiornamento ed eliminazione di servizi. In base allo stato attuale dei servizi in Kubernetes, configura i bilanciatori di carico forniti dal cloud (come gli ELB, i Google LB, o gli Oracle Cloud Infrastructure LB) per riflettere lo stato dei servizi in Kubernetes. Inoltre, assicura che i back-end dei bilanciatori di carico forniti dal cloud siano aggiornati.
2. Kubelet
Il Node Controller contiene l'implementazione dipendente dal cloud della kubelet. Prima dell'introduzione del CCM, la kubelet era responsabile dell'inizializzazione di un nodo con dettagli dipendenti dallo specifico cloud come gli indirizzi IP, le label region/zone e le informazioni sul tipo di istanza. L'introduzione del CCM ha spostato questa operazione di inizializzazione dalla kubelet al CCM.
In questo nuovo modello, la kubelet inizializza un nodo senza informazioni specifiche del cloud. Tuttavia, aggiunge un blocco al nodo appena creato che rende il nodo non selezionabile per eseguire container finché il CCM non inizializza il nodo con le informazioni specifiche del cloud. Il CCM rimuove quindi questo blocco.
Sistema a plug-in
Il cloud controller manager utilizza le interfacce di Go per consentire l'implementazione di implementazioni di qualsiasi cloud. In particolare, utilizza l'interfaccia CloudProvider definita qui.
L'implementazione dei quattro controller generici evidenziati sopra, alcune strutture, l'interfaccia cloudprovider condivisa rimarranno nel core di Kubernetes. Le implementazioni specifiche per i vari cloud saranno costruite al di fuori del core e implementeranno le interfacce definite nel core.
Per ulteriori informazioni sullo sviluppo di plug-in, consultare Developing Cloud Controller Manager.
Autorizzazione
Questa sezione dettaglia l'accesso richiesto dal CCM sui vari API objects per eseguire le sue operazioni.
Node controller
Il Node controller funziona solo con oggetti di tipo Node. Richiede l'accesso completo per ottenere, elencare, creare, aggiornare, applicare patch, guardare ed eliminare oggetti di tipo Node.
v1/Node:
- Get
- List
- Create
- Update
- Patch
- Watch
- Delete
Route controller
Il Route controller ascolta la creazione dell'oggetto Node e configura le rotte in modo appropriato. Richiede l'accesso in lettura agli oggetti di tipo Node.
v1/Node:
- Get
Service controller
Il Service controller resta in ascolto per eventi di creazione, aggiornamento ed eliminazione di oggetti di tipo Servizi, e configura gli endpoint per tali Servizi in modo appropriato.
Per accedere ai Servizi, è necessario il permesso per list e watch. Per aggiornare i Servizi, sono necessari i permessi patch e update.
Per impostare gli endpoint per i Servizi, richiede i permessi create, list, get, watch, e update.
v1/Service:
- List
- Get
- Watch
- Patch
- Update
Others
L'implementazione del core di CCM richiede l'accesso per creare eventi e, per garantire operazioni sicure, richiede l'accesso per creare ServiceAccounts.
v1/Event:
- Create
- Patch
- Update
v1/ServiceAccount:
- Create
L'RBAC ClusterRole per il CCM ha il seguente aspetto:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cloud-controller-manager
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- '*'
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- ""
resources:
- services
verbs:
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- update
- watch
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- get
- list
- watch
- update
Vendor Implementations
I seguenti fornitori di cloud hanno una implementazione di CCM:
Cluster Administration
Le istruzioni complete per la configurazione e l'esecuzione del CCM sono fornite qui.
3.2.3 - Controller
Nella robotica e nell'automazione, un circuito di controllo (control loop) è un un'iterazione senza soluzione di continuità che regola lo stato di un sistema.
Ecco un esempio di un circuito di controllo: il termostato di una stanza.
Quando viene impostata la temperatura, si definisce attraverso il termostato lo stato desiderato. L'attuale temperatura nella stanza è invece lo stato corrente. Il termostato agisce per portare lo stato corrente il più vicino possibile allo stato desiderato accendendo e spegnendo le apparecchiature.
In Kubernetes, i controller sono circuiti di controllo che osservano lo stato del cluster, e apportano o richiedono modifiche quando necessario. Ogni controller prova a portare lo stato corrente del cluster verso lo stato desiderato.Il modello del controller
Un controller monitora almeno una tipo di risorsa registrata in Kubernetes. Questi oggetti hanno una proprietà chiamata spec (specifica) che rappresenta lo stato desiderato. Il o i controller per quella risorsa sono responsabili di mantenere lo stato corrente il più simile possibile rispetto allo stato desiderato.
Il controller potrebbe eseguire l'azione relativa alla risorsa in questione da sé; più comunemente, in Kubernetes, un controller invia messaggi all'API server che a sua volta li rende disponibili ad altri componenti nel cluster. Di seguito troverete esempi per questo scenario.
Controllo attraverso l'API server
Il Job controller è un esempio di un controller nativo in Kubernetes. I controller nativi gestiscono lo stato interagendo con l'API server presente nel cluster.
Il Job è una risorsa di Kubernetes che lancia uno o più Pod per eseguire un lavoro (task) e poi fermarsi.
(Una volta che è stato schedulato, un oggetto Pod diventa parte dello stato desisderato di un dato kubelet).
Quando il Job controller vede un nuovo lavoro da svolgere si assicura che, da qualche parte nel cluster, i kubelet anche sparsi su più nodi eseguano il numero corretto di Pod necessari per eseguire il lavoro richiesto. Il Job controller non esegue direttamente alcun Pod o container bensì chiede all'API server di creare o rimuovere i Pod. Altri componenti appartenenti al control plane reagiscono in base alle nuove informazioni (ci sono nuovi Pod da creare e gestire) e cooperano al completamento del job.
Dopo che un nuovo Job è stato creato, lo stato desiderato per quel Job è il suo completamento. Il Job controller fa sì che lo stato corrente per quel Job sia il più vicino possibile allo stato desiderato: creare Pod che eseguano il lavoro che deve essere effettuato attraverso il Job, così che il Job sia prossimo al completamento.
I controller aggiornano anche gli oggetti che hanno configurato. Ad esempio: una volta che il lavoro relativo ad un dato Job è stato completato, il Job controller aggiorna l'oggetto Job segnandolo come Finished.
(Questo è simile allo scenario del termostato che spegne un certo led per indicare che ora la stanza ha raggiungo la temperatura impostata)
Controllo diretto
A differenza del Job, alcuni controller devono eseguire delle modifiche a parti esterne al cluster.
Per esempio, se viene usato un circuito di controllo per assicurare che ci sia un numero sufficiente di Nodi nel cluster, allora il controller ha bisogno che qualcosa al di fuori del cluster configuri i nuovi Nodi quando sarà necessario.
I controller che interagiscono con un sistema esterno trovano il loro stato desiderato attraverso l'API server, quindi comunicano direttamente con un sistema esterno per portare il loro stato corrente più in linea possibile con lo stato desiderato
(In realtà c'è un controller che scala orizzontalmente i nodi nel cluster. Vedi Cluster autoscaling).
Stato desiderato versus corrente
Kubernetes ha una visione cloud-native dei sistemi, ed è in grado di gestire continue modifiche.
Il cluster viene modificato continuamente durante la sua attività ed il circuito di controllo è in grado di risolvere automaticamente i possibili guasti.
Fino a che i controller del cluster sono in funzione ed in grado di apportare le dovute modifiche, non è rilevante che lo stato complessivo del cluster sia o meno stabile.
Progettazione
Come cardine della sua progettazione, Kubernetes usa vari controller ognuno dei quali è responsabile per un particolare aspetto dello stato del cluster. Più comunemente, un dato circuito di controllo (controller) usa un tipo di risorsa per il suo stato desiderato, ed utilizza anche risorse di altro tipo per raggiungere questo stato desiderato. Per esempio il Job controller tiene traccia degli oggetti di tipo Job (per scoprire nuove attività da eseguire) e degli oggetti di tipo Pod (questi ultimi usati per eseguire i Job, e quindi per controllare quando il loro lavoro è terminato). In questo caso, qualcos'altro crea i Job, mentre il Job controller crea i Pod.
È utile avere semplici controller piuttosto che un unico, monolitico, circuito di controllo. I controller possono guastarsi, quindi Kubernetes è stato disegnato per gestire questa eventualità.
Nota:Ci possono essere diversi controller che creato o aggiornano lo stesso tipo di oggetti. Dietro le quinte, i controller di Kubernetes si preoccupano esclusivamente delle risorse (di altro tipo) collegate alla risorsa primaria da essi controllata.
Per esempio, si possono avere Deployment e Job; entrambe creano Pod. Il Job controller non distrugge i Pod creati da un Deployment, perché ci sono informazioni (labels) che vengono usate dal controller per distinguere i Pod.
I modi per eseguire i controller
Kubernetes annovera un insieme di controller nativi che sono in esecuzione all'interno del kube-controller-manager. Questi controller nativi forniscono importanti funzionalità di base.
Il Deployment controller ed il Job controller sono esempi di controller che vengono forniti direttamente da Kubernetes stesso (ovvero controller "nativi"). Kubernetes consente di eseguire un piano di controllo(control plane) resiliente, di modo che se un dei controller nativi dovesse fallire, un'altra parte del piano di controllo si occuperà di eseguire quel lavoro.
Al fine di estendere Kubernetes, si possono avere controller in esecuzione al di fuori del piano di controllo. Oppure, se si desidera, è possibile scriversi un nuovo controller. È possibile eseguire il proprio controller come una serie di Pod, oppure esternamente rispetto a Kubernetes. Quale sia la soluzione migliore, dipende dalla responsabilità di un dato controller.
Voci correlate
- Leggi in merito Kubernetes control plane
- Scopri alcune delle basi degli oggetti di Kubernetes
- Per saperne di più riguardo alle API di Kubernetes
- Se vuoi creare un tuo controller, guarda i modelli per l'estensibilità in Estendere Kubernetes.
3.3 - Containers
Ogni container che viene eseguito è riproducibile; la pratica di includere le dipendenze all'interno di ciascuno container permette di ottenere sempre lo stesso risultato ad ogni esecuzione del medesimo container.
I Container permettono di disaccoppiare le applicazioni dall'infrastruttura del host su cui vengono eseguite. Questo approccio rende più facile il deployment su cloud o sitemi operativi differenti tra loro.
Immagine di container
L'immagine di un container e' un pacchetto software che contiene tutto ciò che serve per eseguire un'applicazione: il codice sorgente e ciascun runtime necessario, librerie applicative e di sistema, e le impostazioni predefinite per ogni configurazione necessaria.
Un container è immutabile per definizione: non è possibile modificare il codice di un container in esecuzione. Se si ha un'applicazione containerizzata e la si vuole modificare, si deve costruire un nuovo container che includa il cambiamento desiderato, e quindi ricreare il container partendo dalla nuova immagine aggiornata.
Container runtimes
Il container runtime è il software che è responsabile per l'esecuzione dei container.
Kubernetes supporta diversi container runtimes: Docker, containerd, cri-o, rktlet e tutte le implementazioni di Kubernetes CRI (Container Runtime Interface).
Voci correlate
- Leggi in merito immagine di container
- Leggi in merito Pods
3.3.1 - Immagini
L'immagine di un container rappresenta dati binari che incapsulano un'applicazione e tutte le sue dipendenze software. Le immagini sono costituite da pacchetti software eseguibili che possono essere avviati in modalità standalone e su cui si possono fare ipotesi ben precise circa l'ambiente in cui vengono eseguiti.
Tipicamente viene creata un'immagine di un'applicazione ed effettuato il push su un registry (un repository pubblico di immagini) prima di poterne fare riferimento esplicito in un Pod
Questa pagina va a delineare nello specifico il concetto di immagine di un container.
I nomi delle immagini
Alle immagini dei container vengono normalmente attribuiti nomi come pause, example/mycontainer, o kube-apiserver.
Le immagini possono anche contenere l'hostname del registry in cui le immagini sono pubblicate;
ad esempio: registro.fittizio.esempio/nomeimmagine,
ed è possibile che sia incluso nel nome anche il numero della porta; ad esempio: registro.fittizio.esempio:10443/nomeimmagine.
Se non si specifica l'hostname di un registry, Kubernetes assume che ci si riferisca al registry pubblico di Docker.
Dopo la parte relativa al nome dell'immagine si può aggiungere un tag (come comunemente avviene per comandi come docker e podman).
I tag permettono l'identificazione di differenti versioni della stessa serie di immagini.
I tag delle immagini sono composti da lettere minuscole e maiuscole, numeri, underscore (_),
punti (.), e trattini (-).
Esistono regole aggiuntive relative a dove i caratteri separatori (_, -, and .)
possano essere inseriti nel tag di un'immagine.
Se non si specifica un tag, Kubernetes assume il tag latest che va a definire l'immagine disponibile più recente.
Attenzione:Evitate di utilizzare il tag
latestquando si rilasciano dei container in produzione, in quanto risulta difficile tracciare quale versione dell'immagine sia stata avviata e persino più difficile effettuare un rollback ad una versione precente.Invece, meglio specificare un tag specifico come ad esempio
v1.42.0.
Aggiornamento delle immagini
Quando un Deployment,
StatefulSet, Pod, o qualsiasi altro
oggetto che includa un Pod template viene creato per la prima volta, la policy di default per il pull di tutti i container nel Pod
è impostata su IfNotPresent (se non presente) se non specificato diversamente.
Questa policy permette al
kubelet di evitare di fare il pull
di un'immagine se questa è già presente.
Se necessario, si può forzare il pull in ogni occasione in uno dei seguenti modi:
- impostando
imagePullPolicy(specifica per il pull delle immagini) del container suAlways(sempre). - omettendo
imagePullPolicyed usando il tag:latest(più recente) per l'immagine da utilizzare; Kubernetes imposterà la policy suAlways(sempre). - omettendo
imagePullPolicyed il tag per l'immagine da utilizzare. - abilitando l'admission controller AlwaysPullImages.
Nota:Il valore dell'impostazione
imagePullPolicydel container è sempre presente quando l'oggetto viene creato per la prima volta e non viene aggiornato se il tag dell'immagine dovesse cambiare successivamente.Ad esempio, creando un Deployment con un'immagine il cui tag non è
:latest, e successivamente aggiornando il tag di quell'immagine a:latest, il campoimagePullPolicynon cambierà suAlways. È necessario modificare manualmente la policy di pull di ogni oggetto dopo la sua creazione.
Quando imagePullPolicy è definito senza un valore specifico, esso è impostato su Always.
Multi-architecture support nelle immagini
Oltre a fornire immagini binarie, un container registry può fornire un indice delle immagini disponibili per un container.
L'indice di un'immagine può puntare a più file manifest ciascuno per una versione specifica dell'architettura di un container.
L'idea è che si può avere un unico nome per una stessa immagine (ad esempio: pause, example/mycontainer, kube-apiserver) e permettere a diversi sistemi di recuperare l'immagine binaria corretta a seconda dell'architettura della macchina che la sta utilizzando.
Kubernetes stesso tipicamente nomina le immagini dei container tramite il suffisso -$(ARCH).
Per la garantire la retrocompatibilità è meglio generare le vecchie immagini con dei suffissi.
L'idea è quella di generare, ad esempio, l'immagine pause con un manifest che include tutte le architetture supportate,
affiancata, ad esempio, da pause-amd64 che è retrocompatibile per le vecchie configurazioni o per quei file YAML
in cui sono specificate le immagini con i suffissi.
Utilizzare un private registry
I private registry possono richiedere l'utilizzo di chiavi per accedere alle immagini in essi contenute.
Le credenziali possono essere fornite in molti modi:
- configurando i nodi in modo tale da autenticarsi al private registry
- tutti i pod possono acquisire informazioni da qualsiasi private registry configurato
- è necessario che l'amministratore del cluster configuri i nodi in tal senso
- tramite pre-pulled images (immagini pre-caricate sui nodi)
- tutti i pod possono accedere alle immagini salvate sulla cache del nodo a cui si riferiscono
- è necessario effettuare l'accesso come root di sistema su ogni nodo per inserire questa impostazione
- specificando ImagePullSecrets su un determinato pod
- solo i pod che forniscono le proprie chiavi hanno la possibilità di accedere al private registry
- tramite estensioni locali o specifiche di un Vendor
- se si sta utilizzando una configurazione personalizzata del nodo oppure se manualmente, o tramite il cloud provider, si implementa un meccanismo di autenticazione del nodo presso il container registry.
Di seguito la spiegazione dettagliata di queste opzioni.
Configurazione dei nodi per l'autenticazione ad un private registry
Se si sta utilizzando Docker sui nodi, si può configurare il Docker container runtime per autenticare il nodo presso un private container registry.
Questo è un approccio possibile se si ha il controllo sulle configurazioni del nodo.
Nota: Kubernetes di default supporta solo le sezioniauthseHttpHeadersnelle configurazioni relative a Docker. Eventuali helper per le credenziali di Docker (credHelpersocredsStore) non sono supportati.
Docker salva le chiavi per i registri privati in $HOME/.dockercfg oppure nel file $HOME/.docker/config.json.
Inserendo lo stesso file nella lista seguente, kubelet lo utilizzerà per recuperare le credenziali quando deve fare il pull delle immagini.
{--root-dir:-/var/lib/kubelet}/config.json{cwd of kubelet}/config.json${HOME}/.docker/config.json/.docker/config.json{--root-dir:-/var/lib/kubelet}/.dockercfg{cwd of kubelet}/.dockercfg${HOME}/.dockercfg/.dockercfg
Nota: Potrebbe essere necessario impostareHOME=/rootesplicitamente come variabile d'ambiente del processo kubelet.
Di seguito i passi consigliati per configurare l'utilizzo di un private registry da parte dei nodi del cluster. In questo esempio, eseguire i seguenti comandi sul proprio desktop/laptop:
- Esegui
docker login [server]per ogni set di credenziali che vuoi utilizzare. Questo comando aggiornerà$HOME/.docker/config.jsonsul tuo PC. - Controlla il file
$HOME/.docker/config.jsonin un editor di testo per assicurarti che contenga le credenziali che tu voglia utilizzare. - Recupera la lista dei tuoi nodi; ad esempio:
- se vuoi utilizzare i nomi:
nodes=$( kubectl get nodes -o jsonpath='{range.items[*].metadata}{.name} {end}' ) - se vuoi recuperare gli indirizzi IP:
nodes=$( kubectl get nodes -o jsonpath='{range .items[*].status.addresses[?(@.type=="ExternalIP")]}{.address} {end}' )
- se vuoi utilizzare i nomi:
- Copia il tuo file locale
.docker/config.jsonin uno dei path sopra riportati nella lista di ricerca.- ad esempio, per testare il tutto:
for n in $nodes; do scp ~/.docker/config.json root@"$n":/var/lib/kubelet/config.json; done
- ad esempio, per testare il tutto:
Nota: Per i cluster di produzione, utilizza un configuration management tool per poter applicare le impostazioni su tutti i nodi laddove necessario.
Puoi fare una verifica creando un Pod che faccia uso di un'immagine privata; ad esempio:
kubectl apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: private-image-test-1
spec:
containers:
- name: uses-private-image
image: $PRIVATE_IMAGE_NAME
imagePullPolicy: Always
command: [ "echo", "SUCCESS" ]
EOF
pod/private-image-test-1 created
Se tutto funziona correttamente, pochi istanti dopo, si può lanciare il comando:
kubectl logs private-image-test-1
e verificare che il comando restituisca in output:
SUCCESS
Qualora si sospetti che il comando sia fallito, si può eseguire:
kubectl describe pods/private-image-test-1 | grep 'Failed'
In caso di fallimento, l'output sarà simile al seguente:
Fri, 26 Jun 2015 15:36:13 -0700 Fri, 26 Jun 2015 15:39:13 -0700 19 {kubelet node-i2hq} spec.containers{uses-private-image} failed Failed to pull image "user/privaterepo:v1": Error: image user/privaterepo:v1 not found
Bisogna assicurarsi che tutti i nodi nel cluster abbiano lo stesso file .docker/config.json.
Altrimenti i pod funzioneranno correttamente su alcuni nodi ma falliranno su altri.
Ad esempio, se si utilizza l'autoscaling per i nodi, il template di ogni istanza
devono includere il file .docker/config.json oppure montare un disco che lo contenga.
Tutti i pod avranno accesso in lettura alle immagini presenti nel private registry
una volta che le rispettive chiavi di accesso siano state aggiunte nel file .docker/config.json.
Immagini pre-pulled
Nota: Questo approccio è possibile se si ha il controllo sulla configurazione del nodo. Non funzionerà qualora il cloud provider gestisca i nodi e li sostituisca automaticamente.
Kubelet di default prova a fare il pull di ogni immagine dal registry specificato.
Tuttavia, qualora la proprietà imagePullPolicy (specifica di pull dell'immagine) del container sia impostata su IfNotPresent (vale a dire, se non è già presente) oppure su Never (mai),
allora l'immagine locale è utilizzata (in via preferenziale o esclusiva, rispettivamente).
Se si vuole fare affidamento a immagini pre-scaricate per non dover incorrere in una fase di autenticazione presso il registry, bisogna assicurarsi che tutti i nodi nel cluster abbiano scaricato le stesse versioni delle immagini.
Questa procedura può essere utilizzata per accelerare il processo di creazione delle istanze o come alternativa all'autenticazione presso un private registry.
Tutti i pod avranno accesso in lettura a qualsiasi immagine pre-scaricata.
Specificare la proprietà imagePullSecrets su un Pod
Nota: Questo approccio è quello consigliato per l'avvio di container a partire da immagini presenti in registri privati.
Kubernetes da la possibilità di specificare le chiavi del container registry su un Pod.
Creare un Secret tramite Docker config
Esegui il comando seguente, sostituendo i valori riportati in maiuscolo con quelli corretti:
kubectl create secret docker-registry <name> --docker-server=DOCKER_REGISTRY_SERVER --docker-username=DOCKER_USER --docker-password=DOCKER_PASSWORD --docker-email=DOCKER_EMAIL
Se possiedi il file delle credenziali per Docker, anziché utilizzare il comando quì sopra
puoi importare il file di credenziali come un Kubernetes
Secrets.
Creare un Secret a partire da credenziali Docker fornisce la spiegazione dettagliata su come fare.
Ciò è particolarmente utile se si utilizzano più container registry privati,
in quanto il comando kubectl create secret docker-registry genera un Secret che
funziona con un solo private registry.
Nota: I Pod possono fare riferimento ai Secret per il pull delle immagini soltanto nel proprio namespace, quindi questo procedimento deve essere svolto per ogni namespace.
Fare riferimento ad imagePullSecrets in un Pod
È possibile creare pod che referenzino quel Secret aggiungendo la sezione imagePullSecrets alla definizione del Pod.
Ad esempio:
cat <<EOF > pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo
namespace: awesomeapps
spec:
containers:
- name: foo
image: janedoe/awesomeapp:v1
imagePullSecrets:
- name: myregistrykey
EOF
cat <<EOF >> ./kustomization.yaml
resources:
- pod.yaml
EOF
Questo deve esser fatto per ogni Pod che utilizzi un private registry.
Comunque, le impostazioni relative a questo campo possono essere automatizzate inserendo la sezione imagePullSecrets nella definizione della risorsa ServiceAccount.
Visitare la pagina Aggiungere ImagePullSecrets ad un Service Account per istruzioni più dettagliate.
Puoi utilizzarlo in congiunzione al file .docker/config.json configurato per ogni nodo. In questo caso, si applicherà un merge delle credenziali.
Casi d'uso
Ci sono varie soluzioni per configurare i private registry. Di seguito, alcuni casi d'uso comuni e le soluzioni suggerite.
- Cluster in cui sono utilizzate soltanto immagini non proprietarie (ovvero open-source). In questo caso non sussiste il bisogno di nascondere le immagini.
- Utilizza immagini pubbliche da Docker hub.
- Nessuna configurazione richiesta.
- Alcuni cloud provider mettono in cache o effettuano il mirror di immagini pubbliche, il che migliora la disponibilità delle immagini e ne riduce il tempo di pull.
- Utilizza immagini pubbliche da Docker hub.
- Cluster con container avviati a partire da immagini proprietarie che dovrebbero essere nascoste a chi è esterno all'organizzazione, ma
visibili a tutti gli utenti abilitati nel cluster.
- Utilizza un private Docker registry.
- Esso può essere ospitato da Docker Hub, o da qualche altra piattaforma.
- Configura manualmente il file .docker/config.json su ogni nodo come descritto sopra.
- Oppure, avvia un private registry dietro il tuo firewall con accesso in lettura libero.
- Non è necessaria alcuna configurazione di Kubernetes.
- Utilizza un servizio di container registry che controlli l'accesso alle immagini
- Esso funzionerà meglio con una configurazione del cluster basata su autoscaling che con una configurazione manuale del nodo.
- Oppure, su un cluster dove la modifica delle configurazioni del nodo non è conveniente, utilizza
imagePullSecrets.
- Utilizza un private Docker registry.
- Cluster con immagini proprietarie, alcune delle quali richiedono un controllo sugli accessi.
- Assicurati che l'admission controller AlwaysPullImages sia attivo. Altrimenti, tutti i Pod potenzialmente possono avere accesso a tutte le immagini.
- Sposta i dati sensibili un un Secret, invece di inserirli in un'immagine.
- Un cluster multi-tenant dove ogni tenant necessiti di un private registry.
- Assicurati che l'admission controller AlwaysPullImages sia attivo. Altrimenti, tutti i Pod di tutti i tenant potrebbero potenzialmente avere accesso a tutte le immagini.
- Avvia un private registry che richieda un'autorizzazione all'accesso.
- Genera delle credenziali di registry per ogni tenant, inseriscile in dei Secret, e popola i Secret per ogni namespace relativo ad ognuno dei tenant.
- Il singolo tenant aggiunge così quel Secret all'impostazione imagePullSecrets di ogni namespace.
Se si ha la necessità di accedere a più registri, si può generare un Secret per ognuno di essi.
Kubelet farà il merge di ogni imagePullSecrets in un singolo file virtuale .docker/config.json.
Voci correlate
3.3.2 - Container Environment
Questa pagina descrive le risorse disponibili nei Container eseguiti in Kubernetes.
Container environment
Quando si esegue un Container in Kubernetes, le seguenti risorse sono rese disponibili:
- Un filesystem, composto dal file system dell'image e da uno o più volumes.
- Una serie di informazioni sul Container stesso.
- Una serie di informazioni sugli oggetti nel cluster.
Informazioni sul Container
L' hostname di un Container è il nome del Pod all'interno del quale è eseguito il Container.
È consultabile tramite il comando hostname o tramite la funzione
gethostname
disponibile in libc.
Il nome del Pod e il namespace possono essere resi disponibili come environment variables attraverso l'uso delle downward API.
Gli utenti possono aggiungere altre environment variables nella definizione del Pod; anche queste saranno disponibili nel Container come tutte le altre environment variables definite staticamente nella Docker image.
Informazioni sul cluster
Al momento della creazione del Container è generata una serie di environment variables con la lista di servizi in esecuzione nel cluster. Queste environment variables rispettano la sintassi dei Docker links.
Per un servizio chiamato foo che è in esecuzione in un Container di nome bar, le seguenti variabili sono generate:
FOO_SERVICE_HOST=<host su cui il servizio è attivo>
FOO_SERVICE_PORT=<porta su cui il servizio è pubblicato>
I servizi hanno un indirizzo IP dedicato e sono disponibili nei Container anche via DNS se il DNS addon è installato nel cluster.
Voci correlate
- Approfondisci Container lifecycle hooks.
- Esegui un tutorial su come definire degli handlers per i Container lifecycle events.
3.3.3 - Container Lifecycle Hooks
Questa pagina descrive come i Container gestiti con kubelet possono utilizzare il lifecycle hook framework dei Container per l'esecuzione di codice eseguito in corrispondenza di alcuni eventi durante il loro ciclo di vita.
Overview
Analogamente a molti framework di linguaggi di programmazione che hanno degli hooks legati al ciclo di vita dei componenti, come ad esempio Angular, Kubernetes fornisce ai Container degli hook legati al loro ciclo di vita dei Container. Gli hook consentono ai Container di essere consapevoli degli eventi durante il loro ciclo di gestione ed eseguire del codice implementato in un handler quando il corrispondente hook viene eseguito.
Container hooks
Esistono due tipi di hook che vengono esposti ai Container:
PostStart
Questo hook viene eseguito successivamente alla creazione del container. Tuttavia, non vi è garanzia che questo hook venga eseguito prima dell'ENTRYPOINT del container. Non vengono passati parametri all'handler.
PreStop
Questo hook viene eseguito prima della terminazione di un container a causa di una richiesta API o
di un evento di gestione, come ad esempio un fallimento delle sonde di liveness/startup, preemption,
risorse contese e altro. Una chiamata all'hook di PreStop fallisce se il container è in stato
terminated o completed e l'hook deve finire prima che possa essere inviato il segnale di TERM per
fermare il container. Il conto alla rovescia per la terminazione del Pod (grace period) inizia prima dell'esecuzione
dell'hook PreStop, quindi indipendentemente dall'esito dell'handler, il container terminerà entro
il grace period impostato. Non vengono passati parametri all'handler.
Una descrizione più dettagliata riguardante al processo di terminazione dei Pod può essere trovata in Terminazione dei Pod.
Implementazione degli hook handler
I Container possono accedere a un hook implementando e registrando un handler per tale hook. Ci sono due tipi di handler che possono essere implementati per i Container:
- Exec - Esegue un comando specifico, tipo
pre-stop.sh, all'interno dei cgroup e namespace del Container. Le risorse consumate dal comando vengono contate sul Container. - HTTP - Esegue una richiesta HTTP verso un endpoint specifico del Container.
Esecuzione dell'hook handler
Quando viene richiamato l'hook legato al lifecycle del Container, il sistema di gestione di Kubernetes
esegue l'handler secondo l'azione dell'hook, httpGet e tcpSocket vengono eseguiti dal processo kubelet,
mentre exec è eseguito nel Container.
Le chiamate agli handler degli hook sono sincrone rispetto al contesto del Pod che contiene il Container.
Questo significa che per un hook PostStart, l'ENTRYPOINT e l'hook si attivano in modo asincrono.
Tuttavia, se l'hook impiega troppo tempo per essere eseguito o si blocca, il container non può raggiungere lo
stato di running.
Gli hook di PreStop non vengono eseguiti in modo asincrono dall'evento di stop del container; l'hook
deve completare la sua esecuzione prima che l'evento TERM possa essere inviato. Se un hook di PreStop
si blocca durante la sua esecuzione, la fase del Pod rimarrà Terminating finchè il Pod non sarà rimosso forzatamente
dopo la scadenza del suo terminationGracePeriodSeconds. Questo grace period si applica al tempo totale
necessario per effettuare sia l'esecuzione dell'hook di PreStop che per l'arresto normale del container.
Se, per esempio, il terminationGracePeriodSeconds è di 60, e l'hook impiega 55 secondi per essere completato,
e il container impiega 10 secondi per fermarsi normalmente dopo aver ricevuto il segnale, allora il container
verrà terminato prima di poter completare il suo arresto, poiché terminationGracePeriodSeconds è inferiore al tempo
totale (55+10) necessario perché queste due cose accadano.
Se un hook PostStart o PreStop fallisce, allora il container viene terminato.
Gli utenti dovrebbero mantenere i loro handler degli hook i più leggeri possibili. Ci sono casi, tuttavia, in cui i comandi di lunga durata hanno senso, come il salvataggio dello stato del container prima della sua fine.
Garanzia della chiamata dell'hook
La chiamata degli hook avviene almeno una volta, il che significa
che un hook può essere chiamato più volte da un dato evento, come per PostStart
o PreStop.
Sta all'implementazione dell'hook gestire correttamente questo aspetto.
Generalmente, vengono effettuate singole chiamate agli hook. Se, per esempio, la destinazione di hook HTTP non è momentaneamente in grado di ricevere traffico, non c'è alcun tentativo di re invio. In alcuni rari casi, tuttavia, può verificarsi una doppia chiamata. Per esempio, se un kubelet si riavvia nel mentre dell'invio di un hook, questo potrebbe essere chiamato per una seconda volta dopo che il kubelet è tornato in funzione.
Debugging Hook handlers
I log di un handler di hook non sono esposti negli eventi del Pod.
Se un handler fallisce per qualche ragione, trasmette un evento.
Per il PostStart, questo è l'evento di FailedPostStartHook,
e per il PreStop, questo è l'evento di FailedPreStopHook.
Puoi vedere questi eventi eseguendo kubectl describe pod <pod_name>.
Ecco alcuni esempi di output di eventi dall'esecuzione di questo comando:
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1 {default-scheduler } Normal Scheduled Successfully assigned test-1730497541-cq1d2 to gke-test-cluster-default-pool-a07e5d30-siqd
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Pulling pulling image "test:1.0"
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Created Created container with docker id 5c6a256a2567; Security:[seccomp=unconfined]
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Pulled Successfully pulled image "test:1.0"
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Started Started container with docker id 5c6a256a2567
38s 38s 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Killing Killing container with docker id 5c6a256a2567: PostStart handler: Error executing in Docker Container: 1
37s 37s 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Killing Killing container with docker id 8df9fdfd7054: PostStart handler: Error executing in Docker Container: 1
38s 37s 2 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} Warning FailedSync Error syncing pod, skipping: failed to "StartContainer" for "main" with RunContainerError: "PostStart handler: Error executing in Docker Container: 1"
1m 22s 2 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Warning FailedPostStartHook
Voci correlate
- Approfondisci Container environment.
- Esegui un tutorial su come definire degli handlers per i Container lifecycle events.
3.4 - Amministrazione del Cluster
3.4.1 - Proxy in Kubernetes
Questa pagina spiega i proxy utilizzati con Kubernetes.
Proxy
Esistono diversi proxy che puoi incontrare quando usi Kubernetes:
- Il kubectl proxy:
- viene eseguito sul computer di un utente o in un pod - collega un localhost address all'apiserver di Kubernetes - il client comunica con il proxy in HTTP - il proxy comunica con l'apiserver in HTTPS - individua l'apiserver - aggiunge gli header di autenticazione
- è un proxy presente nell'apiserver - collega un utente al di fuori del cluster agli IP del cluster che altrimenti potrebbero non essere raggiungibili - è uno dei processi dell'apiserver - il client comunica con il proxy in HTTPS (o HTTP se l'apiserver è configurato in tal modo) - il proxy comunica con il target via HTTP o HTTPS come scelto dal proxy utilizzando le informazioni disponibili - può essere utilizzato per raggiungere un nodo, un pod o un servizio - esegue il bilanciamento del carico quando viene utilizzato per raggiungere un servizio
- Il kube proxy:
- è eseguito su ciascun nodo - fa da proxy per comunicazioni UDP, TCP e SCTP - non gestisce il protocollo HTTP - esegue il bilanciamento del carico - è usato solo per raggiungere i servizi
- Un proxy/bilanciatore di carico di fronte agli apiserver:
- la sua esistenza e implementazione variano da cluster a cluster (ad esempio nginx) - si trova tra i client e uno o più apiserver - funge da bilanciatore di carico se ci sono più di un apiserver.
- Cloud Load Balancer su servizi esterni:
- sono forniti da alcuni fornitori di servizi cloud (ad es. AWS ELB, Google Cloud Load Balancer)
- vengono creati automaticamente quando il servizio Kubernetes ha tipo LoadBalancer
- solitamente supporta solo UDP / TCP
- il supporto SCTP dipende dall'implementazione del bilanciatore di carico del provider cloud
- l'implementazione varia a seconda del provider cloud.
Gli utenti di Kubernetes in genere non devono preoccuparsi alcun proxy, se non i primi due tipi. L'amministratore del cluster in genere assicurerà che gli altri tipi di proxy siano impostati correttamente.
Richiedere reindirizzamenti
I proxy hanno sostituito le funzioni di reindirizzamento. I reindirizzamenti sono stati deprecati.
3.5 - Esempio di modello di concetto
Nota: Assicurati anche di creare una voce nel sommario per il tuo nuovo documento.
Questa pagina spiega ...
Comprendendo ...
Kubernetes fornisce ...
Usando ...
Usare
Voci correlate
[Sezione opzionale]
- Ulteriori informazioni su Scrivere un nuovo argomento.
- Vedi Uso dei modelli di pagina - Modello di concetto su come utilizzare questo modello.
4 - Tutorials
Questa sezione della documentazione di Kubernetes contiene i tutorials. Un tutorial mostra come raggiungere un obiettivo più complesso di un singolo task. Solitamente un tutorial ha diverse sezioni, ognuna delle quali consiste in una sequenza di più task. Prima di procedere con vari tutorial, raccomandiamo di aggiungere il Glossario ai tuoi bookmark per riferimenti successivi.
Per cominciare
-
Kubernetes Basics è un approfondito tutorial che aiuta a capire cosa è Kubernetes e che permette di testare in modo interattivo alcune semplici funzionalità di Kubernetes.
Configurazione
Stateless Applications
Stateful Applications
Clusters
Servizi
Voci correlate
Se sei interessato a scrivere un tutorial, vedi Utilizzare i Page Templates per informazioni su come creare una tutorial page e sul tutorial template.
4.1 - Hello Minikube
Questo tutorial mostra come eseguire una semplice applicazione in Kubernetes utilizzando Minikube e Katacoda. Katacoda permette di operare su un'installazione di Kubernetes dal tuo browser.
Nota: Come alternativa, è possibile eseguire questo tutorial installando minikube localmente.
Obbiettivi
- Rilasciare una semplice applicazione su Minikube.
- Eseguire l'applicazione.
- Visualizzare i log dell'applicazione.
Prima di cominciare
Questo tutorial fornisce una container image che utilizza NGINX per risponde a tutte le richieste con un echo che visualizza i dati della richiesta stessa.
Crea un Minikube cluster
-
Click Launch Terminal
Nota: Se hai installato Minikube localmente, eseguiminikube start. -
Apri la console di Kubernetes nel browser:
minikube dashboard -
Katacoda environment only: In alto alla finestra del terminale, fai click segno più, e a seguire click su Select port to view on Host 1.
-
Katacoda environment only: Inserisci
30000, a seguire click su Display Port.
Crea un Deployment
Un Kubernetes Pod è un gruppo di uno o più Containers,
che sono uniti tra loro dal punto di vista amministrativo e che condividono lo stesso network.
Il Pod in questo tutorial ha un solo Container. Un Kubernetes
Deployment monitora lo stato del Pod ed
eventualmente provvedere a farlo ripartire nel caso questo termini. L'uso dei Deployments è la
modalità raccomandata per gestire la creazione e lo scaling dei Pods.
-
Usa il comando
kubectl createper creare un Deployment che gestisce un singolo Pod. Il Pod eseguirà un Container basato sulla Docker image specificata.kubectl create deployment hello-node --image=k8s.gcr.io/echoserver:1.4 -
Visualizza il Deployment:
kubectl get deploymentsL'output del comando è simile a:
NAME READY UP-TO-DATE AVAILABLE AGE hello-node 1/1 1 1 1m -
Visualizza il Pod creato dal Deployment:
kubectl get podsL'output del comando è simile a:
NAME READY STATUS RESTARTS AGE hello-node-5f76cf6ccf-br9b5 1/1 Running 0 1m -
Visualizza gli eventi del cluster Kubernetes:
kubectl get events -
Visualizza la configurazione di
kubectl:kubectl config view
Nota: Per maggiori informazioni sui comandi dikubectl, vedi kubectl overview.
Crea un Service
Con le impostazioni di default, un Pod è accessibile solamente dagli indirizzi IP interni
al Kubernetes cluster. Per far si che il Container hello-node sia accessibile dall'esterno
del Kubernetes virtual network, è necessario esporre il Pod utilizzando un
Kubernetes Service.
-
Esponi il Pod su internet untilizzando il comando
kubectl expose:kubectl expose deployment hello-node --type=LoadBalancer --port=8080Il flag
--type=LoadBalancerindica la volontà di esporre il Service all'esterno del Kubernetes cluster. -
Visualizza il Servizio appena creato:
kubectl get servicesL'output del comando è simile a:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE hello-node LoadBalancer 10.108.144.78 <pending> 8080:30369/TCP 21s kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 23mNei cloud providers che supportano i servizi di tipo load balancers, viene fornito un indirizzo IP pubblico per permettere l'acesso al Service. Su Minikube, il service type
LoadBalancerrende il Service accessibile attraverso il comandominikube service. -
Esegui il comando:
minikube service hello-node -
Katacoda environment only: Fai click segno più, e a seguire click su Select port to view on Host 1.
-
Katacoda environment only: Fai attenzione al numero di 5 cifre visualizzato a fianco di
8080nell'output del comando. Questo port number è generato casualmente e può essere diverso nel tuo caso. Inserisci il tuo port number nella textbox, e a seguire fai click su Display Port. Nell'esempio precedente, avresti scritto30369.Questo apre un finestra nel browser dove l'applicazione visuallizza l'echo delle richieste ricevute.
Attiva gli addons
Minikube include un set addons che possono essere attivati, disattivati o eseguti nel ambiente Kubernetes locale.
-
Elenca gli addons disponibili:
minikube addons listL'output del comando è simile a:
addon-manager: enabled dashboard: enabled default-storageclass: enabled efk: disabled freshpod: disabled gvisor: disabled helm-tiller: disabled ingress: disabled ingress-dns: disabled logviewer: disabled metrics-server: disabled nvidia-driver-installer: disabled nvidia-gpu-device-plugin: disabled registry: disabled registry-creds: disabled storage-provisioner: enabled storage-provisioner-gluster: disabled -
Attiva un addon, per esempio,
metrics-server:minikube addons enable metrics-serverL'output del comando è simile a:
metrics-server was successfully enabled -
Visualizza i Pods ed i Service creati in precedenza:
kubectl get pod,svc -n kube-systemL'output del comando è simile a:
NAME READY STATUS RESTARTS AGE pod/coredns-5644d7b6d9-mh9ll 1/1 Running 0 34m pod/coredns-5644d7b6d9-pqd2t 1/1 Running 0 34m pod/metrics-server-67fb648c5 1/1 Running 0 26s pod/etcd-minikube 1/1 Running 0 34m pod/influxdb-grafana-b29w8 2/2 Running 0 26s pod/kube-addon-manager-minikube 1/1 Running 0 34m pod/kube-apiserver-minikube 1/1 Running 0 34m pod/kube-controller-manager-minikube 1/1 Running 0 34m pod/kube-proxy-rnlps 1/1 Running 0 34m pod/kube-scheduler-minikube 1/1 Running 0 34m pod/storage-provisioner 1/1 Running 0 34m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/metrics-server ClusterIP 10.96.241.45 <none> 80/TCP 26s service/kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP 34m service/monitoring-grafana NodePort 10.99.24.54 <none> 80:30002/TCP 26s service/monitoring-influxdb ClusterIP 10.111.169.94 <none> 8083/TCP,8086/TCP 26s -
Disabilita
metrics-server:minikube addons disable metrics-serverL'output del comando è simile a:
metrics-server was successfully disabled
Clean up
Adesso puoi procedere a fare clean up delle risorse che hai creato nel tuo cluster:
kubectl delete service hello-node
kubectl delete deployment hello-node
Eventualmente, puoi stoppare la Minikube virtual machine (VM):
minikube stop
Eventualmente, puoi cancellare la Minikube VM:
minikube delete
Voci correlate
- Approfondisci la tua conoscenza dei Deployments.
- Approfondisci la tua conoscenza di Rilasciare applicazioni.
- Approfondisci la tua conoscenza dei Services.